
SRE(Site Reliability Engineering)は、Googleが2003年に提唱したシステム運用のアプローチです。
本記事では、SREの定義からDevOpsとの違い、SLI/SLO/SLAなどの実践手法、年収700-800万円のキャリア
パス、インフラエンジニアからの転職ステップまで、最新の調査データを基に解説します。
※この記事の英語版をお読みになりたい方は、こちらになります。(Read this article in English, please click here!)

- SREの定義とGoogleによる誕生の背景、DevOpsとの明確な違いと実装関係について
- SLI/SLO/SLA、エラーバジェット、トイル削減などの実践で使う指標と手法について
- 年収700-800万円のキャリアパスと、インフラエンジニアからの転職に必要な具体的ステップについて

1. SRE(Site Reliability Engineering)とは何か

SREは、Googleが提唱したシステムの信頼性をソフトウェアエンジニアリングで実現するアプローチです。
従来の手作業中心の運用から脱却し、コードを書いて問題を解決するという発想の転換により、開発速度と安定性の両立を可能にします。
SREの定義:システムの信頼性をソフトウェアで実現する
SRE(Site Reliability Engineering、サイト信頼性エンジニアリング)の概念は、2003年から2004年にかけてGoogleのベン・トレイナー・スロース氏により提唱されました。
当初は、組織が開発チームからの頻繁な更新の中でソフトウェアアプリケーションの信頼性を維持することを目的に導入されました。
従来のシステム運用では、専門の「システム管理者」が手作業でサーバーを監視し、障害対応やメンテナンスを行うのが一般的でした。
しかしSREは、「ソフトウェアエンジニアに運用を任せる」というアイデアのもと、信頼性を単なる運用業務ではなく「機能」として扱い、コードを書いて解決するという思想を掲げています。
出典:Google Cloud, Site Reliability Engineering (SRE)
SREが誕生した背景
Google社内で直面した深刻なスケール課題がありました。
Googleのサービスは、数百万ユーザーから数億ユーザーへと急激に成長し、従来型の「システム管理者による手作業運用」では限界に達したのです。
サービス規模の拡大に対し管理者を増員するスケールモデルでは人件費が増加し、手作業による設定変更やデプロイではミスが頻発しました。
属人的な知識に依存するため特定の担当者がいなければ障害対応ができず、深夜や休日の緊急対応が常態化しエンジニアの疲弊も深刻化していました。
こうした課題に対し、Googleは「運用を自動化で解決する」というエンジニアリング的解答を見出しました。
人を増やすのではなく、コードを書いてシステムが自律的に動くようにする。この発想が、SREの原点です。
SREの本質:開発速度と安定性のバランス
SREの最も革新的な点は、「スピードと信頼性はトレードオフではなく、両立可能である」という考え方にあります。
従来、開発チームは新機能を早くリリースしたいと考え、運用チームはシステムを安定させたいと考えるため、両者は対立しがちでした。
SREは、この対立を「エラーバジェット」という革新的な判断基準で解消します。エラーバジェットとは、SLO(Service Level Objective、サービスレベル目標)で設定した目標値と100%の差分を「許容可能なエラーの予算」として扱う概念です。
予算内であれば積極的に新機能をリリースでき、予算を使い切ったら安定化作業を優先します。
この仕組みにより、開発と運用は「データに基づく客観的な意思決定」ができるようになります。SREの目指すものは「完璧な安定性(100%)」ではありません。
ユーザーは99.9%と100%の違いを体感できないため、その差分をビジネス成長を支えるイノベーションに使うべきだという「適切な信頼性」の追求こそが、SREの本質です。
SREの3つの柱
SREを支える基盤は、運用の自動化、信頼性の定量化、組織文化の変革という3つの要素で構成されます。
運用の自動化
手作業を徹底的に排除しコードによる自動化を推進します。
Infrastructure as Code (IaC) でTerraformやCloudFormationを使ってインフラをコード管理し、JenkinsやGitHub ActionsでCI/CDパイプラインを構築します。
信頼性の定量化
感覚や経験ではなくデータとメトリクスに基づいて判断します。SLI/SLO/SLAによって稼働率、レイテンシ、エラー率などを数値で管理し、PrometheusやDatadogで継続的に監視します。
組織文化の変革
技術的な仕組みだけでなく組織の考え方そのものを変えます。
Blameless Post-mortemsで個人ではなくシステムを改善し、インシデントを共有財産として組織全体で学び、開発と運用が対立ではなく共通目標に向けた協力関係を構築します。
2. SREとDevOpsの違い:「哲学」と「実装」の関係
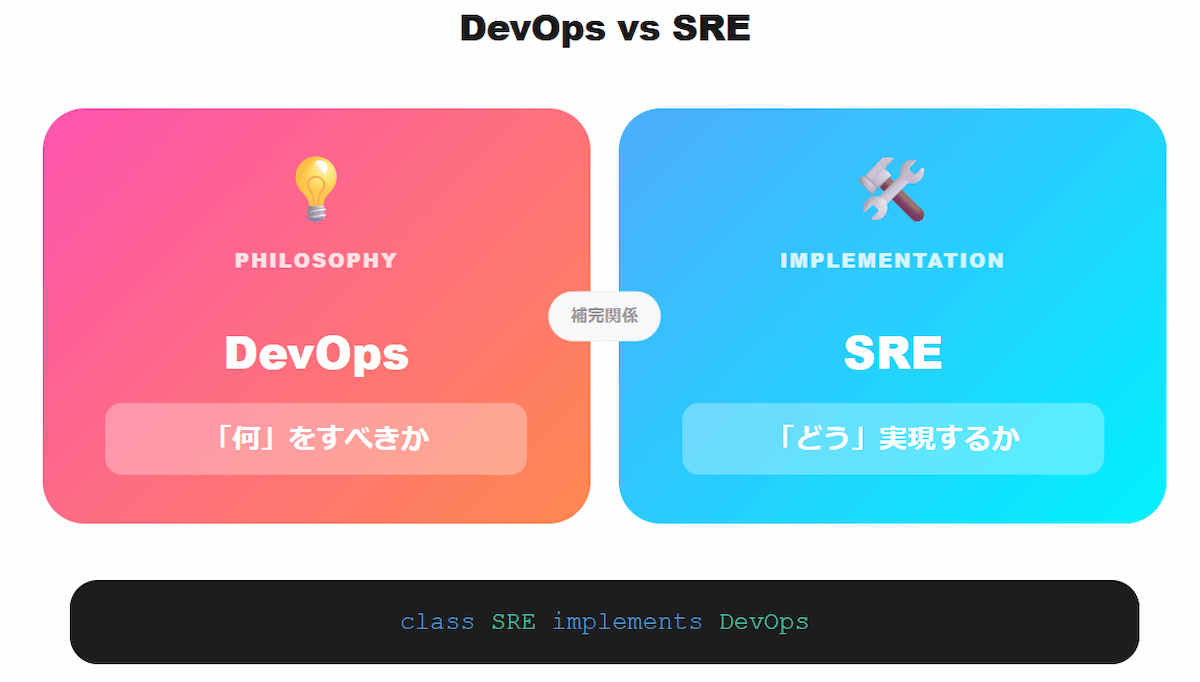
SREとDevOpsは混同されがちですが、明確な違いがあります。
DevOpsが「何をすべきか」という文化・哲学を示すのに対し、SREは「どう実現するか」という具体的な実装手法を提供します。両者は対立ではなく、補完し合う関係にあります。
DevOpsは「何をすべきか」、SREは「どう実現するか」
SREとDevOpsの関係性は明確に整理できます。DevOpsは文化・マインドセット・原則(What to do)であり、SREは具体的な実践手法・実装方法(How to do)です。
Google SREチームの責任者であったベン・トレイナー・スロース氏は、この関係を「class SRE implements DevOps」という表現で説明しました。
つまり、DevOpsという抽象的な概念(インターフェース)を、SREという具体的な実装(クラス)で実現するという関係です。
出典:Google Cloud, Site Reliability Engineering (SRE)
比較表:DevOpsとSREの違い
| 観点 | DevOps | SRE |
|---|---|---|
| 性質 | 文化・哲学・マインドセット | 具体的な職務・役割・実装 |
| 範囲 | 開発から運用までの全体最適 | 運用の信頼性に特化 |
| 指標 | 定性的な改善目標 | 定量的な目標設定(SLO等) |
| 人材 | 開発者と運用者の協働文化 | ソフトウェアエンジニアが運用 |
| 起源 | コミュニティ主導(2009年頃〜) | Google社内から(2003年頃〜) |
転職市場では「DevOpsエンジニア」と「SREエンジニア」は別の職種として扱われることが多く、SREの方がより技術的な専門性が求められ、年収も高い傾向にあります。
Findy 2024年の調査によると、SREエンジニアの年収中央値は700-800万円であるのに対し、インフラエンジニアは600-650万円、DevOpsエンジニアは650-750万円となっています。
出典:AWS, What is Site Reliability Engineering?
出典:Findy, インフラ・SREエンジニア実態調査2024
3. SRE(Site Reliability Engineering)の実践手法:6つの重要原則

SREを実践する上で押さえるべき6つの重要原則があります。
- SLI/SLO/SLAによる信頼性の定量化
- エラーバジェットによる判断基準
- トイル削減
- ポストモーテム
- 段階的変更
- オブザーバビリティ
です。
これらの原則が相互に連携し、信頼性の高い運用を実現します。
原則1:SLI/SLO/SLAで信頼性を定量化する
SLI(Service Level Indicator)
システムの健全性を測る具体的なメトリクスです。代表的なSLIには、可用性(正常に応答した割合)、レイテンシ(応答速度)、エラー率(失敗したリクエストの割合)があります。
ECサイトの場合、商品ページの表示速度は95%のリクエストが200ms以内、購入処理の成功率は99.9%以上といった指標を設定します。
SLO(Service Level Objective)
SLIの目標値として設定します。ビジネス要件と技術的実現性のバランスを取ることが重要であり、100%を目指さないのがSREの重要なポイントです。
実例としては、月間稼働率99.9%(43.2分のダウンタイム許容)、API応答時間は95パーセンタイルで300ms以内といった設定が一般的です。
SLA(Service Level Agreement)
顧客との契約上の約束です。SLOより緩い値を設定してバッファを確保し、違反時の補償内容(返金、クレジット等)を明記します。なぜSLOよりSLAを緩く設定するのか。
これは測定誤差の吸収、予期しない問題への対応余地、法的リスクの軽減、および「完璧主義の排除」によってイノベーションを阻害しないためです。
出典:Google Cloud, Service Level Objectives
原則2:エラーバジェットで開発と運用のバランスを取る
エラーバジェットとは、「許容可能なエラーの予算」という概念です。SLO 100%との差分が「使える予算」となり、予算内であれば新機能リリースが可能ですが、超過したら安定化を優先します。
月間稼働率99.9%の場合、30日×24時間×60分=43,200分のうち、エラーバジェットは43.2分となります。つまり月に43.2分のダウンタイムまで許容され、この予算内で新機能リリースやメンテナンスを実施します。
エラーバジェットの意思決定フローは明確です。バジェット残あり(使用率50%)の状況では積極的に新機能リリースが可能です。
バジェット残少(使用率80%)の状況では重要度の高いリリースのみを慎重に実施します。バジェット超過(使用率105%)の状況ではリリースを完全凍結し、安定化作業に集中します。
開発チームは明確なリリース判断基準が得られ、SREチームは安定化の優先度を数値で説明でき、経営層はイノベーションと安定性のバランスを可視化できます。
出典:Google SRE Book, Embracing Risk
原則3:トイル(Toil)を削減し自動化を推進する
Googleによるトイルの5つの特徴は、手作業(Manual)、反復的(Repetitive)、自動化可能(Automatable)、戦術的(Tactical)、拡張性なし(No enduring value)というものです。
SREの時間配分には明確な原則があります。運用業務(トイル)は50%以下に抑え、エンジニアリング業務は50%以上を確保します。この比率を守ることで、持続可能な運用体制を維持できます。
トイル削減の実践ステップは4段階です。1週間の作業をすべて記録してトイルを可視化し、影響度(頻度×所要時間×自動化の容易さ)で優先順位を付け、簡単なものから自動化を実装し、削減された時間を記録して効果を測定します。
デプロイ作業の自動化の成功事例では、手作業で2時間かかっていた作業をJenkins + Terraform + Ansibleで完全自動化し、10分(ボタン押すだけ)に短縮しました。月間14.7時間削減と品質向上を実現しました。
出典:Google SRE Book, Eliminating Toil
原則4:ポストモーテムで失敗から学ぶ組織文化
ポストモーテムとは、インシデント発生後の根本原因分析です。最も重要な原則は、個人を責めず、システムと過程を改善することです。
この「Blameless Post-mortems」の文化は、組織における心理的安全性の向上に寄与します)人を責めると情報が隠蔽され、失敗から学ぶ機会を失い、次のインシデントを防げなくなります。
ポストモーテムは7つの要素で構成されます。概要、タイムライン、根本原因、影響、対応内容、再発防止策、学んだことを詳細に記録します。
組織的な効果として、同じ失敗の再発防止、チーム全体の知識レベル向上、心理的安全性の醸成があります。
出典:Google SRE Book, Postmortem Culture
原則5:段階的な変更とツールによるリスク管理
カナリアリリースでは、新バージョンを一部ユーザー(1-5%)に先行適用し、問題がなければ段階的に拡大(10%→50%→100%)します。
Blue-Greenデプロイでは、新環境を本番と並行して構築し、完全に準備できたらトラフィックを瞬時に切り替えます。フィーチャーフラグでは、機能のON/OFFをコード変更なく制御します。
原則6:オブザーバビリティによる可視化
4つのゴールデンシグナルは、レイテンシ(応答時間)、トラフィック(需要量)、エラー(失敗率)、サチュレーション(リソース使用率)です。
3つの柱(Three Pillars of Observability)は、メトリクス、ログ、トレースで構成されます。
SREを支える主要ツールとして、
- モニタリングにはPrometheus・Datadog・Grafana、
- ログ管理にはElasticsearch・Splunk、
- CI/CDにはJenkins・GitLab CI・GitHub Actions、
- IaCにはTerraform・CloudFormation、
- コンテナにはKubernetes・Docker
があります。
出典:AWS, What is Site Reliability Engineering?
4. SREエンジニアに必要なスキルと年収

SREエンジニアには、プログラミング、クラウド・インフラ、コンテナ、IaC、モニタリングといった幅広い技術スキルが求められます。
年収中央値は700-800万円で、インフラエンジニアより15-20%高い水準です。技術の希少性と責任の重さが高年収の理由となっています。
求められる技術スキル
プログラミング言語
Pythonが最重要です(自動化スクリプト、データ処理、監視ツール連携)。次にGo(Kubernetes等のツール開発)、Shell/Bash(日常的な運用作業)が求められます。
クラウド・インフラ技術
AWS(最も求人が多い)、GCP(Google発祥のため親和性高い)、Azure(エンタープライズ企業で需要)のいずれか1つ以上に精通する必要があります。
推奨資格はAWS認定ソリューションアーキテクト – アソシエイト(SAA)、Google Cloud Associate Cloud Engineerです。
コンテナ・オーケストレーション
Dockerは必須で、Kubernetesは最重要です。2025年時点で、SRE求人の約70%がKubernetesスキルを求めています。推奨資格はCKA(Certified Kubernetes Administrator)です。
IaCとCI/CD
Terraform、Ansible、Jenkins、GitLab CI / GitHub Actions、Gitの知識が必要です。
モニタリング・オブザーバビリティ
Prometheus + Grafana(最も人気の組み合わせ)、ELKスタック(ログ管理)、Datadog、New Relicなどのツールを使いこなす必要があります。
技術以外のソフトスキルとして、問題解決能力、コミュニケーション力、データ分析力、ドキュメンテーション、学習能力・適応力が求められます。
SREエンジニアの年収データ(2024年最新)
日本国内の年収中央値は700〜800万円です(Findy 2024年調査)。
経験年数別では、1-3年で500-650万円、3-5年で650-850万円、5-7年で800-1,000万円、7年以上で900-1,200万円となっています。
| 職種 | 平均年収 | 年収レンジ |
|---|---|---|
| SREエンジニア | 750万円 | 600〜1,200万円 |
| インフラエンジニア | 620万円 | 500〜900万円 |
| 差額 | +130万円 | +15〜20% |
SREの年収が高い理由は、
- 需要に対して供給が圧倒的に不足(希少性)、
- コーディング+インフラ+運用の3つが必要(スキルセット)、
- 24/7のシステム安定性に責任(責任の重さ)、
- ダウンタイムが直接売上に影響(ビジネス影響度)、
- Kubernetes等の高度な技術が必要(技術レベル)
であることです。
企業規模別では、
- 外資系IT企業で900〜1,500万円、
- メガベンチャーで800〜1,200万円、
- SIer・大手IT企業で650〜1,000万円
です。
年収アップのポイントとして、Kubernetes認定資格(CKA)取得やAWS/GCP上級資格取得で+100〜200万円、ビジネスレベルの英語力で+100〜300万円、チームリード経験で+150〜300万円の効果があります。
出典:Findy, インフラ・SREエンニア実態調査2024
■日本でエンジニアとしてキャリアアップしたい方へ
海外エンジニア転職支援サービス『 Bloomtech Career 』にご相談ください。「英語OK」「ビザサポートあり」「高年収企業」など、外国人エンジニア向けの求人を多数掲載。専任のキャリアアドバイザーが、あなたのスキル・希望に合った最適な日本企業をご紹介します。
▼簡単・無料!30秒で登録完了!まずはお気軽にご連絡ください!
Bloomtech Careerに無料相談してみる
5. インフラエンジニアからSREへのキャリアパス

インフラエンジニアからSREへの転職は、適切な準備をすれば3-6ヶ月で実現可能です。
コーディングスキルの習得、クラウド・コンテナ技術の実践、実務経験の積み上げという3ステップで、年収15-20%アップと市場価値の向上を目指せます。
なぜ今、SREへの転職が注目されているのか
クラウドネイティブ化の加速、DXの推進とシステムの重要性増加、深刻な人材不足(求人倍率約8倍)という3つの市場トレンドがあります。
インフラエンジニアがSREに転身するメリットとして、年収15-20%アップの可能性、コーディングスキルが身につく、市場価値の向上、リモートワーク可の求人が多いことが挙げられます。
SREへの転職に必要な準備:3ステップ×12ヶ月
- ステップ1:コーディングスキルの習得(3〜6ヶ月)では、Python基礎を1〜2ヶ月で学習し、実務での自動化実践を2〜4ヶ月行います。学習リソースはUdemy「Python 3 入門 + 応用」、書籍「退屈なことはPythonにやらせよう」、実践として既存の運用作業を1つずつ自動化します。
- ステップ2:クラウド・コンテナ技術の実践(3〜6ヶ月)では、クラウド基礎とAWS認定を2〜3ヶ月で習得し、Docker + Kubernetesを3〜4ヶ月で学習します。AWS認定ソリューションアーキテクト(SAA)やCKA(Certified Kubernetes Administrator)の取得を推奨します。
- ステップ3:実務経験の積み上げと転職準備(3〜6ヶ月)では、現職でのSRE的実践(運用作業の棚卸し、小さな自動化、監視の改善提案)を2〜3ヶ月行い、ポートフォリオ作成(GitHubで自動化スクリプト集、Terraformサンプルコード、技術ブログ)を1〜2ヶ月行い、転職活動の準備(履歴書・職務経歴書の作成)を1〜2ヶ月行います。
職務経歴書のアピールポイント
NG例(抽象的)
- 「サーバーの運用管理を行った」
- 「障害対応をした」
OK例(具体的・定量的)
- 「月間1,000万PVのECサイト(300台のサーバー)の運用を担当。Prometheusによる監視基盤を構築し、障害検知時間を平均15分→3分に短縮」
- 「Ansibleによる構成管理の自動化で、サーバー初期構築時間を8時間→30分に削減。年間200時間の工数削減を実現」
転職活動の進め方
求人の探し方として、転職エージェント(レバテックキャリア、マイナビITエージェント)、求人サイト(Green、Wantedly、LinkedIn、Findy)、企業に直接応募があります。
良い求人の特徴は、「SREチームの立ち上げメンバー募集」「インフラエンジニアからのキャリアチェンジ歓迎」「育成制度充実」、SLO/SLI・エラーバジェットへの言及、使用技術スタックが明確であることです。
要注意な求人は、「SRE」と書いてあるが実態は従来型の運用業務(24時間365日の運用監視が主業務)、「コーディングは不要」と書いてある、求人票が曖昧というものです。
6. 2026年のSREトレンドと今後の展望

2025年のSRE業界では、AI・機械学習との融合、システム複雑化によるトイル増加、オブザーバビリティツールの統合、日本国内コミュニティの成長という4つの大きなトレンドが見られます。
AI時代でもSREエンジニアの価値は高く、むしろその重要性は増しています。
AI・機械学習とSREの融合
Catchpoint 2025レポートによると、SREがAIに期待することの上位は、
- 異常検知の自動化(52%)、
- 根本原因分析の支援(47%)、
- 予測的アラート(40%)
です。
AIがSREに与える影響として、「AIは補助ツールとして活用」と考えるのが62%で、「AIが人間に完全に置き換わる時代はまだ遠い」という認識が主流です。
AI活用の具体例
ログ解析の自動化(機械学習で異常パターンを自動検出)、障害予測(メトリクスの傾向からインシデント予兆を検知)、アラート最適化(過去のインシデントから学習し重要度を自動判定)、自動修復(簡単な障害への自動対応)があります。
AIに代替されにくいSREの業務
アーキテクチャ設計、SLO設定(ビジネス要件の理解が必要)、複雑な障害の根本原因分析、組織文化の醸成、ステークホルダーとのコミュニケーションがあります。
出典:Catchpoint, The SRE Report 2025, https://www.scribd.com/document/829748871/The-SRE-Report-2025-Catchpoint
トイルの増加パラドックス
Catchpoint 2025レポートによると、トイルが増加したと答えたのは42%でした。
増加の主な原因は、マイクロサービス化(管理対象の爆発的増加)、マルチクラウド対応、新技術の学習コスト、セキュリティ要件の厳格化です。
解決のアプローチとして、Platform Engineeringの導入があります。これは開発者体験の向上に特化し、開発者が自分でインフラを操作できるプラットフォームを構築してSREの負担を減らす手法です。
出典:Catchpoint, The SRE Report 2025
オブザーバビリティの統合
Dynatrace調査によると、85%がオブザーバビリティプラットフォームの統一を望んでいます。
現状では、メトリクスはPrometheus、ログはElasticsearch、トレースはJaeger、APMはNew Relic、インフラ監視はDatadogと、5つのツールを行き来する必要があり、相関分析が困難で学習コストが高い状況です。
2025年のトレンドとして、1つのプラットフォームでメトリクス・ログ・トレースを統合、OpenTelemetryの標準化、ベンダーロックインの回避が進んでいます。
出典:Dynatrace, State of SRE Report 2022
日本国内のSREコミュニティの成長
SRE NEXT 2025の参加者は1,272人(過去最大規模)で、主要なトピックとしてKubernetes運用のベストプラクティス、SLO設定の実例、AI活用事例、ポストモーテム文化の醸成が議論されました。
国内企業の成功事例として、LINE(数億ユーザーのメッセージングサービス、SREチーム100人以上)、メルカリ(月間2,000万人が利用、SLO駆動開発)、Oisix(中堅企業の事例、小規模SREチーム5人でスタート)があります。
7. SRE(Site Reliability Engineering)についてのよくある質問(FAQ)

SREエンジニアへの転職やキャリア形成に関して、多くの方が抱く疑問に回答します。必要な経験年数、年収水準、学ぶべきスキル、オンコール対応の実態など、実践的な質問に具体的にお答えします。
Q1. SREエンジニアになるには、どれくらいの経験が必要ですか?
インフラエンジニアとして3年以上の経験があり、基礎的なプログラミングスキル(Python等)があれば、SREエンジニアへの転職は十分可能です。
実際の転職事例では、インフラ経験3年+Python学習6ヶ月+AWS認定資格取得で成功した例が多くあります。
Q2. SREとインフラエンジニアの違いは何ですか?
最も大きな違いは「コーディング比重」です。SREはプログラミングで運用を自動化することが主業務の50%を占めます(50%ルール)。
また、SLI/SLO/SLAなどの定量的指標で信頼性を管理し、年収もSREの方が15-20%程度高い傾向にあります。
Q3. SREエンジニアの年収はどれくらいですか?
日本国内の年収中央値は700-800万円です(Findy 2024年調査)。なお、2025年開催のSRE NEXT 2025には1,272人が来場しており、コミュニティの熱量も高まっています。
経験年数別では、1-3年で500-650万円、3-5年で650-850万円、5-7年で800-1,000万円、7年以上で900-1,200万円です。外資系IT企業では900-1,500万円の水準です。
出典:Findy, インフラ・SREエンジニア実態調査2024, https://findy-code.io/
Q4. どのプログラミング言語を学ぶべきですか?
最優先はPythonです。理由は、SREの自動化タスクに最適、AWS/GCP SDKの充実、学習リソースが豊富、求人での要求が最多であることです。
次にGo(Kubernetes等のツール開発)、Shell/Bash(日常的な運用作業)が求められます。
Q5. Kubernetesは必須ですか?
2025年時点で、SRE求人の約70%がKubernetesスキルを求めています。特にWeb系企業やクラウドネイティブ企業では必須レベルです。
転職を有利に進めるなら、Kubernetes基礎(CKA資格レベル)の習得を強く推奨します。
Q6. オンコール対応(深夜・休日の障害対応)は必須ですか?
SREの業務には一般的にオンコール対応が含まれます。ただし、優れたSREチームほど自動化とモニタリングにより深夜の緊急対応を減らすことを目指します。
企業によっては、複数人でのローテーション制(月2-3回程度)、オンコール手当の支給(1回5,000-20,000円)があります。
Q7. リモートワークは可能ですか?
SREはリモートワークと親和性が高い職種です。2024年時点で、フルリモート可が約40%の求人、ハイブリッド(週2-3日出社)が約45%です。
特にスタートアップやIT企業ではリモート勤務が一般的です。
Q8. SREになって後悔することはありますか?
挑戦的な点として、オンコール対応のプレッシャー、常に新しい技術を学ぶ必要がある、インシデント時のストレスがあります。
しかし、多くのSREが、技術的に成長できる環境、高い年収、ビジネスへの直接的な貢献実感、働き方の柔軟性というメリットが課題を上回ると評価しています。
8. SREとは?年収700-800万円・DevOpsとの違い・転職方法のまとめ

SRE(Site Reliability Engineering)は、Googleが提唱した「システムの信頼性をソフトウェアエンジニアリングで実現する」アプローチです。
従来の手作業中心の運用から脱却し、コードによる自動化、SLI/SLO/SLAによる定量管理、エラーバジェットによる開発と運用のバランス、ポストモーテムによる学習文化を組み合わせることで、ビジネスの成長を支える信頼性基盤を構築します。
現在、SREエンジニアの需要は急増しており、年収中央値は700-800万円です。
インフラエンジニアから適切な準備をすれば3-6ヶ月で転職可能で、Pythonによる自動化スキル、AWSなどのクラウド知識、Kubernetesの実務経験が重視されます。
AI時代においてもその価値は高まり続けており、継続的な学習と適応がSREエンジニアとして成功する鍵です。
















