
Redisとは、データをメモリ上で管理することでミリ秒未満の応答速度を実現するインメモリデータベースです。
キャッシュ・セッション管理・ランキング処理など、現代のWebシステムで広く採用されており、KVSカテゴリでは世界1位の普及度を誇ります。
この記事では、Redisの仕組み・5つのデータ型・実務でのユースケース・導入時のセキュリティ注意点まで、実務に実務に即した観点から解説します。
- Redisがなぜ高速なのか、仕組みのレベルで理解できる
- 5つの基本データ型と代表的なユースケースを把握できる
- 導入前に知っておくべきセキュリティと最新動向がわかる

1.Redisとは何か―インメモリデータベースの基本を理解する

「普通のデータベースと何が違うのか」―Redisを初めて学ぶときに真っ先に生まれる疑問です。ここではRedisの定義と分類、既存のデータベースとの違いを整理します。
RedisはKVS型のNoSQLデータベース
Redisの正式名称はRemote Dictionary Server(リモート・ディクショナリ・サーバー)です。
キーと値をセットで管理するKVS(Key-Value Store)として動作するNoSQLデータベースの一種で、単純なKVSを超えた「データ構造ストア」という独自のポジションを持っています。
開発言語はC言語です。2009年にイタリアの技術者Salvatore Sanfilippoが、リアルタイムWebログ解析ツールのパフォーマンス課題を解決するために開発しました。
DB-Enginesの全データベース総合ランキングでは世界8位、KVSカテゴリでは世界1位の普及度を記録しています。
(出典:DB-Engines)
RDBとの違いはデータの置き場所
通常のRDB(MySQL・PostgreSQLなど)はデータをディスクに保存するため、読み書きのたびにI/O処理が発生します。
Redisはデータをすべてメモリ(RAM)上に保持するため、このI/O待ちがゼロになります。結果として、応答速度に大きな差(サブミリ秒 vs 数〜数十ミリ秒)が生まれます。
実務では「よくアクセスするデータはRedis、長期保存が必要なデータはRDB」という使い分けが基本です。Redisをキャッシュ層に置くことで、RDBへのリクエスト数を減らす設計が多くの現場で採用されています。
Redisの基本仕様まとめ
| 項目 | 内容 |
|---|---|
| 正式名称 | Remote Dictionary Server |
| 主な分類 | インメモリデータベース・NoSQL・KVS |
| 開発言語 | C言語 |
| データ保持 | メモリ(RAM)上(永続化機能あり) |
| 応答速度 | サブミリ秒(1ミリ秒未満) |
| ライセンス | ライセンス ソースアベイラブル・ライセンス(RSALv2およびSSPLv1 / バージョン7.4以降) |
2.Redisが高速な理由―主な技術的要因を解説する
Redisが速い理由は「メモリを使っているから」だけではありません。
ソフトウェアの設計レベルでも徹底した効率化が行われており、3つの根拠が組み合わさって高速性を実現しています。
メモリはディスクより圧倒的に速い
HDDはディスクの回転とヘッドの物理的な移動を伴うため、アクセスに数ミリ秒かかります。
NVMe SSDでも数十マイクロ秒です。メモリ(RAM)のアクセス時間は数十ナノ秒で、SSDの約1,000倍、HDDの約10万倍の速さです。Redisはこのメモリの速さをそのままパフォーマンスに活かしています。
デバイス別アクセス時間の比較
| デバイス | アクセス時間の目安 | メモリとの比較 |
|---|---|---|
| CPUキャッシュ(L1/L2) | 数ナノ秒 | より速い |
| メモリ(RAM) | 数十ナノ秒 | 基準 |
| SSD(NVMe) | 数十マイクロ秒 | 約1,000倍遅い |
| HDD(7,200rpm) | 数ミリ秒 | 約10万倍遅い |
シングルスレッドでロック処理をなくす設計
マルチスレッドの問題点
Redisはリクエスト処理をシングルスレッドで行います。マルチスレッド環境では、複数のスレッドが同じデータに同時アクセスするときに「ロック(排他制御)」が必要です。
このロック処理が増えると、待ち時間が生じてパフォーマンスが落ちます。
Redisがシングルスレッドで高速を実現できる理由
Redisはメインのスレッドをシングルスレッドにすることで、データ操作におけるロック処理を不要にしました。
加えて、イベント駆動型のノンブロッキングI/O(epoll・kqueue)を採用し、待機時間も排除しています。
これにより、1台のサーバーで毎秒数十万〜数百万件のリクエストを処理できます。
C言語実装で処理のムダをなくす
RedisはすべてC言語で実装されています。JavaやPythonのように仮想マシンやインタープリタを介す必要がなく、OSと直接やり取りするコードとして動作します。
メモリ管理を含むすべての処理が低レベルで最適化されているため、余分なオーバーヘッドが発生しません。これがサブミリ秒の応答を安定して維持できる理由のひとつです。
3.Redisの5つのデータ型と実務での使い方を理解する

Redisが「データ構造ストア」と呼ばれるのは、単純なKVS以上に多様なデータ型をサポートしているためです。
各データ型には得意な処理があり、使い分けることでアプリケーション側のロジックをシンプルに保てます。5つの基本データ型を実務での活用場面とあわせて確認します。
文字列型(Strings)―最も汎用的なデータ型
文字列型(Strings)はRedisの基本データ型で、テキスト・オブジェクト・バイナリデータを最大512MBまで保存できます。カウンターのインクリメント(INCRコマンド)やビット演算にも対応しています。
ページキャッシュ・アクセスカウンター・セッショントークンの保存など、幅広い用途で使われています。
リスト型(Lists)―順番を保ったメッセージ管理
リスト型(Lists)は挿入した順番に並んだ文字列のリストです。
先頭・末尾への追加と削除(LPUSH/RPOPコマンド)が高速に処理されます。メッセージキューの実装や、タイムライン(最新投稿一覧)の保持に向いています。
セット型(Sets)―重複なしの集合演算をサーバーで処理
セット型(Sets)は重複を許さない、順序なしの集合です。
積集合・和集合・差集合をサーバーサイドで計算できるため、アプリ側の処理を減らせます。
タグ管理・共通フォロワーの抽出・ユニークIPの集計など、「重複を取り除いた集合の計算」が必要な場面で役立ちます。
ソート済みセット型(Sorted Sets)―ランキング実装の最適解
ソート済みセット型(Sorted Sets)は各要素にスコアを付け、スコア順に自動で並べ替える集合です。
スコアの更新と順位の取得をO(log N)で処理できるため、RDBのCOUNT/ORDER BYよりも効率的です。ゲームのリーダーボードやEコマースの商品ランキングなど、リアルタイムで順位が変わる機能に最適です。
ハッシュ型(Hashes)―オブジェクトの一部だけ読み書き
ハッシュ型(Hashes)はフィールドと値をペアで持つデータ型です。
オブジェクト全体ではなく、特定のフィールドだけを高速に読み書きできます。ユーザープロフィールのキャッシュや設定情報の管理など、構造化されたデータを扱う用途に向いています。
5つのデータ型とユースケース一覧
| データ型 | 特徴 | 代表的なユースケース |
|---|---|---|
| Strings | 汎用・最大512MB | キャッシュ・カウンター |
| Lists | 順序付きリスト | メッセージキュー・タイムライン |
| Sets | 重複なし集合 | タグ管理・共通フォロワー抽出 |
| Sorted Sets | スコア順自動整列 | ランキング・リーダーボード |
| Hashes | フィールド・値ペア | ユーザープロフィール管理 |
Redis Stackが提供する高度なデータ型(補足)
Redis Stackなどのパッケージでは、さらに専門的なデータ型も使えます。
- ビットマップ:大規模ユーザーのログイン状況を1ビット単位で管理し、メモリを節約する
- HyperLogLog:約12KBのメモリでユニーク数を誤差1%以内で推定する
- Streams:Kafkaのようなログ追記型のメッセージ処理に対応する
- Geospatial:緯度経度をもとにした近傍検索・距離計算に対応する
4.Redisの主なユースケース―実務でどう活用されているか
Redisが実務で選ばれる場面は、ある程度パターンが決まっています。
代表的な活用パターンを確認します。
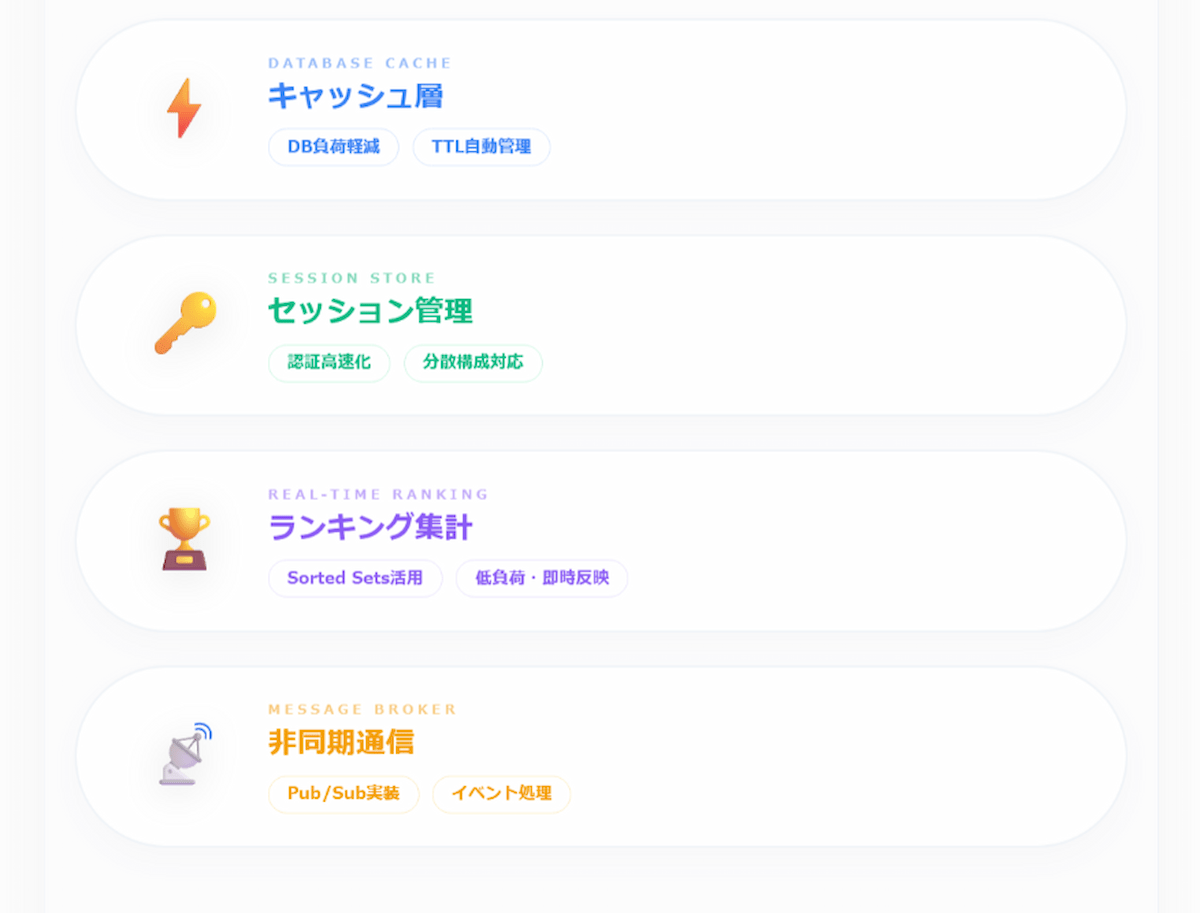
キャッシュ層としての活用―最も広く使われるパターン
Redisの活用法で最も一般的なのが、データベースへの負荷を下げるキャッシュ層としての利用です。
よく参照される検索結果・商品情報・マスターデータなどをRedisに保持することで、RDBへのアクセス回数を大幅に減らせます。
TTL(有効期限)を設定すれば、古いデータが残り続けるリスクも自動で管理できます。
セッション管理でユーザー認証情報を高速処理
ログイン中のセッションIDとユーザー情報をRedisに保持することで、認証処理を速くできます。
Webサーバーを複数台並べる構成では、サーバー間でセッション情報を共有する仕組みが必要です。
Redisは複数サーバーから共通でアクセスできる高速セッションストアとして機能するため、スケールアウト構成で特に重要な役割を担います。
ランキング・集計処理をソート済みセットで効率化
ゲームのスコアランキングやEコマースの閲覧数集計では、ソート済みセット型(Sorted Sets)が広く使われています
RDBでCOUNTやORDER BYを使ってランキングを生成すると、データが増えるほど処理が重くなります。
Redisのソート済みセットはスコアの更新と順位の取得をO(log N)で処理できるため、リアルタイムのランキングを軽い負荷で維持できます。
メッセージブローカーとしての活用
RedisはPub/Sub機能やStreamsを使ったリアルタイムのイベント処理にも対応しています。
マイクロサービス間の非同期通信で、KafkaやRabbitMQの補完・代替として採用されるケースも増えています。
小〜中規模のシステムでは、専用のメッセージブローカーを別途導入しなくても同等の機能を実現できる点が評価されています。
■日本でエンジニアとしてキャリアアップしたい方へ
海外エンジニア転職支援サービス『 Bloomtech Career 』にご相談ください。「英語OK」「ビザサポートあり」「高年収企業」など、外国人エンジニア向けの求人を多数掲載。専任のキャリアアドバイザーが、あなたのスキル・希望に合った最適な日本企業をご紹介します。
▼簡単・無料!30秒で登録完了!まずはお気軽にご連絡ください!
Bloomtech Careerに無料相談してみる
5.Redisの信頼性を支える永続化と高可用性の仕組み

「メモリ上のデータは電源が落ちたら消えるのでは」という疑問は、Redisを検討するうえでよく出てきます。
Redisはこの点に対応するため、データの永続化・レプリケーション・クラスタリングという3つの仕組みを備えています。
RDBとAOF―2つの方式でデータをディスクに保存
RDB(Redis Database File)は、定期的にメモリ上のデータをディスクにスナップショットとして書き出す方式です。
ファイルが小さくリカバリも速いのが特長ですが、最後のスナップショット以降の書き込みデータは失われるリスクがあります。
AOF(Append Only File)は、すべての書き込み操作をログとして追記し続ける方式です。1秒ごと、または全操作ごとにディスクへ同期できるため、データの整合性を高く保てます。
実務ではRDBとAOFを組み合わせた運用が推奨されており、バックアップはRDB、直近データの保護はAOFで担う構成が一般的です。
RDB・AOFの特性比較
| 方式 | 特徴 | 向いている用途 |
|---|---|---|
| RDB | 軽量・高速リカバリ | バックアップ用途 |
| AOF | 整合性が高い | 厳密なデータ保護が必要な場合 |
| RDB+AOF併用 | バランス型 | 本番環境での推奨構成 |
レプリケーションとSentinelで障害に強い構成を実現
レプリケーション―読み取り負荷の分散とデータ保護
Redisはマスター(書き込み担当)のデータを複数のスレーブ(読み取り専用)に非同期でコピーするレプリケーション機能を持っています。
読み取り負荷の分散と、マスター障害時のデータ保護を同時に実現できます。
Redis Sentinel―障害時の自動フェイルオーバー
Redis Sentinelはインスタンスを常時監視し、マスターがダウンした際に自動でスレーブをマスターに切り替えます(フェイルオーバー)。
この仕組みにより、障害が起きても自動で復旧できる高可用性構成を組めます。
Redis Clusterで大規模データへのスケールアウトに対応
Redis Clusterは、データをハッシュスロット単位で複数ノードに自動で分散する機能です。
単一インスタンスでは扱いきれない大規模データも、クラスター構成にすることで数千台規模まで拡張できます。大規模なWebサービスやゲームプラットフォームでも採用されている実績のある仕組みです。
6.Redisのセキュリティ注意点―導入前に必ず確認すべきこと

Redisは使いやすく導入しやすい反面、設定を誤ると深刻なセキュリティリスクにつながります。
導入前にリスクと対策を把握しておくことが重要です。
デフォルト設定のまま公開するとマルウェアの標的に
認証なし公開によるマルウェア悪用リスク
Redisはもともと「信頼できるネットワーク内での利用」を前提に設計されたデータベースです。
認証なしでインターネット上に公開された状態のままにしておくと、クリプトマイニングマルウェアに悪用される事案が継続的に報告されています。
CVE-2024-46981―深刻度9.8のRCE脆弱性
CVE-2024-46981(LuaスクリプトのRCE脆弱性)はNVDのCVSSスコアで9.8(Critical)と評価されており、パッチを当てていない環境ではリモートから任意のコードを実行されるリスクがあります。
バージョン管理と迅速なパッチ適用が欠かせません。
(出典:NVD )
必ず実施すべき4つのセキュリティ対策
Redisを安全に運用するために、以下の4つの対策を必ず実施してください。
- バインド設定:bindコマンドで外部からのアクセスを制限し、信頼できるネットワークからのみ接続を許可する
- ACL(アクセス制御リスト):ユーザーごとにコマンドの実行権限を細かく設定し、不要な操作を禁止する
- パスワード認証+TLS暗号化:認証を必須にし、通信をTLSで暗号化することで盗聴・不正アクセスを防ぐ
- 危険コマンドのリネーム・無効化:FLUSHALL・CONFIGなどのコマンドを推測されにくい名前に変更するか、無効化する
7.Redisの最新動向―ライセンス変更とAI活用の広がり

Redisは技術面だけでなく、ライセンスや利用環境の面でも大きな変化が起きています。
商用利用やクラウド利用を検討しているエンジニアは、最新の動向を把握しておくことが重要です。
2024年のライセンス変更―オープンソースからソースアベイラブルへ
Redis 7.4以降、従来の三条項BSDライセンスからRSALv2・SSPLv1へと変更されました。
クラウドベンダーがマネージドサービスとしてRedisを提供することに制限が加わる内容です。
個人学習や社内利用のみであれば影響は小さいですが、商用サービスやSaaS提供を行う事業者はライセンス条件をしっかり確認する必要があります。
ValkeyのフォークによるオープンソースRedisの継続
このライセンス変更を受け、Linux Foundation主導で「Valkey」というRedisのフォーク版が継続開発されています。
AWSやGoogle CloudなどのクラウドプロバイダーはすでにValkeyへの対応を進めており、マネージドRedisサービスの代替として普及が広がっています。
プロジェクトの利用形態に応じて、Redis・Valkeyのどちらを選ぶかを確認しておくことが実務上のポイントになっています。
AI・機械学習基盤としての需要拡大
Redis for AIとして、ベクトル検索・フィーチャーストア・セマンティック検索への活用が広がっています。
大規模言語モデル(LLM)のコンテキスト管理や埋め込みベクトルの高速検索にRedisが使われる場面も増えており、AIアプリケーションの基盤として注目度が高まっています。
データベース管理システム市場全体の年平均成長率(CAGR)は約13〜14%と予測されており、KVSカテゴリ世界1位の地位を維持しながら、AI時代のインフラとして需要がさらに拡大しています。
(出典:Fortune Business Insights 、Mordor Intelligence )
8.まとめ―Redisとは何かを押さえておくべき理由

Redisはメモリ上でデータを管理するインメモリデータベースです。
シングルスレッドモデルとC言語実装による高速処理で、キャッシュ・セッション管理・ランキング・メッセージ処理など幅広い場面で活用されています。
5つの基本データ型と豊富な拡張機能を持ち、永続化・レプリケーション・クラスタリングにより本番環境での信頼性も確保されています。
2024年のライセンス変更やAI連携の拡大といった変化の中にあっても、KVSカテゴリ世界1位の地位を維持し続けているRedisの仕組みと動向を理解しておくことは、現代のエンジニアにとって大きな武器になります。
















