「Hadoop(ハドゥープ)」という名前を業務や技術書で見かけながら、具体的な仕組みがよくわからないというエンジニアは多いはずです。
この記事では、Hadoopの基本的な定義から3つのコアコンポーネントの役割、Apache Sparkとの使い分け、国内外の活用事例、そしてキャリアとしての将来性まで、順を追って解説します。
- Hadoopの基本的な仕組みと3つのコアコンポーネント(HDFS・MapReduce・YARN)の役割について
- HadoopとApache Sparkの違いと、2つの技術の正しい使い分けについて
- Hadoopエンジニアの市場価値と、データエンジニアへのキャリアパスについて

1. Hadoopとは何か?定義と名前の由来をわかりやすく解説
Hadoop(ハドゥープ)とは、複数のコンピューターを連携させてビッグデータを分散処理するためのオープンソースミドルウェアです。
Apache Software Foundationが管理するプロジェクトで、1台の高性能サーバーに頼るのではなく、多数の汎用サーバーを束ねることでペタバイト級のデータを低コスト・高い耐障害性で扱えるよう設計されています。
ひと言で言えば「大量のデータを多くのコンピューターで手分けして処理し、結果をまとめる」技術です。
クラウドが普及した現在も、大規模なバッチ処理の基盤として多くの企業で使われており、データエンジニアリングを学ぶうえで押さえておきたい技術のひとつです。
Hadoopは「黄色い象のぬいぐるみ」が名前の由来
Hadoopという名前には、技術とはひと味違う微笑ましいエピソードがあります。
主要開発者のDoug Cutting(ダグ・カッティング)氏の子どもが、黄色い象のぬいぐるみに「Hadoop」という名前をつけていたことが由来です。
この象はそのままプロジェクトの公式マスコットになりました。
「象は丈夫で長寿、しかも群れで協力して働く」というイメージが、多数のサーバーが連携して大量データを処理するHadoopの特性と重なるため、開発コミュニティでも気に入られています。
Hadoopはもともと2004年にDoug Cutting氏がApache Nutch(全文検索エンジン)のサブプロジェクトとして開発を始め、2008年にApacheのトップレベルプロジェクトに昇格しました。
(出典:Apache Hadoop – Wikipedia)
Hadoopが生まれた背景——ビッグデータ爆発の時代
データ量の急増と既存技術の限界
Hadoopが登場した2000年代初頭は、インターネットの急速な広がりによってWebログ、ソーシャルメディア、EC購買履歴など、従来のリレーショナルデータベース(RDBMS)では処理しきれないほどのデータが生まれていた時代でした。
IDC Japanの調査によると、国内のビッグデータ/アナリティクス市場は2027年まで年平均成長率(CAGR)14.3%で拡大すると予測されています。
また、Fortune Business Insightsの統計では、2025年末までに世界で生成されるデータ量は181ゼタバイトに達するとされています。
こうした「データ量の爆発」に対し、1台のサーバー性能を上げ続けるやり方ではコストが膨らみすぎることが明らかになりました。
Hadoop誕生のきっかけ——Googleの論文
そこで登場したのが「安価なサーバーを大量に並べてデータを分担処理する」というHadoopのアプローチです。
GoogleがGFS(Google File System)とMapReduceに関する論文を2003〜2004年に発表したことが、Hadoop誕生の直接的なきっかけとなりました。
(出典:IDCが2024年の国内ビッグデータ/アナリティクス市場を予測 – CodeZine / Fortune Business Insights – ビッグデータ分析市場)
2. Hadoopの仕組み——3つのコアコンポーネントを理解する

Hadoopは単体のソフトウェアではなく、複数のコンポーネントが連携して動くフレームワークです。
中核となるのが「HDFS」「MapReduce」「YARN」の3つで、これらはHadoopの三種の神器とも呼べる存在です。
- HDFS:データを分散して保存するストレージ層
- MapReduce:分散したデータを並列処理する演算エンジン
- YARN:クラスター全体のリソース(CPU・メモリ)を管理する司令塔
処理の流れを大まかに説明すると、HDFSに保存された大量データに対して、YARNがリソース配分を決め、MapReduceジョブを各ノードに割り当てて実行します。
この3つが一体となって、ペタバイト規模のデータ処理が実現します。
(出典:Apache Hadoop 公式サイト)
HDFS——データを分散して安全に保存する仕組み
HDFSの基本構造
HDFS(Hadoop Distributed File System)は、大容量のファイルを複数のサーバー(ノード)に分割して保存する分散ファイルシステムです。
通常のファイルシステムがデータを1台のディスクに書き込むのに対し、HDFSはファイルを「ブロック」(デフォルト128MB)という単位に分割し、クラスター内の複数ノードへ自動的に振り分けます。
レプリケーションによる耐障害性
HDFSの大きな特徴が「レプリケーション(複製)」です。デフォルト設定では各ブロックが3つのノードにコピーして保存されます。
1台のサーバーが壊れてもコピーが別ノードに残っているため、データを自動で復旧できます。高価な専用ストレージを使わなくても、高い信頼性を低コストで実現できます。
NameNodeとDataNode
HDFSは「NameNode」と「DataNode」の2種類のノードで構成されます。
NameNodeは「どのブロックがどのDataNodeにあるか」というメタデータ(目次のような情報)を管理し、DataNodeが実際のデータを保存します。
データを取り出す際はまずNameNodeに問い合わせ、場所を確認してから該当のDataNodeへアクセスする仕組みです。
(出典:Apache HDFS Architecture Guide)
MapReduce——大量データを分割・集約して高速処理する仕組み
MapReduceの3ステップ処理フロー
MapReduceは、大量のデータを「分割して処理し、結果をまとめる」という処理モデルです。
以下の3ステップで進みます。
| ステップ | 処理内容 | ワードカウント例 |
|---|---|---|
| Map(マップ) | 入力データを小さな単位に分割し、キーと値のペア(Key-Value)を生成する | 各単語を取り出して「(単語, 1)」のペアを生成 |
| Shuffle(シャッフル) | 同じキーを持つデータをまとめ、Reduceノードへ送る | 同じ単語のペアを同一ノードへ集約 |
| Reduce(リデュース) | キーごとに値を集計して最終結果を出力する | 各単語の出現回数を合計して出力 |
並列処理による高速化
MapReduceの強みは、Map処理とReduce処理を多数のノードで同時に実行できる点です。
たとえば10億行のログファイルを処理する場合、1,000台のノードで一斉にMap処理を走らせれば、処理時間を単純計算で約1,000分の1に短縮できます。
ただし処理結果をその都度ディスクに書き込む方式のため、インメモリ処理のApache Sparkと比べると速度面で劣るケースもあります。
(出典:Apache MapReduce Tutorial)
YARN——クラスターリソースを管理する司令塔
YARNの役割
YARN(Yet Another Resource Negotiator)は、Hadoopクラスター全体のCPUやメモリを一元管理するリソースマネージャーです。
ジョブの実行要求を受け付け、各ノードの空きリソースを把握したうえで、最適なノードにタスクを割り当てます。
MRv1からYARNへのバージョンアップ
Hadoop 1.x系(MRv1)では、リソース管理とジョブ管理がMapReduceの中に一体化されており、MapReduceしか動かせない制約がありました。
Hadoop 2.xで導入されたYARN(MRv2)では、リソース管理が独立した層として切り出され、MapReduceのほかにApache SparkやApache Tezなど、さまざまなフレームワークを同じクラスター上で動かせるようになりました。
このバージョンアップがHadoopの使える幅を大きく広げました。
(出典:Apache Hadoop – Wikipedia(YARNの項))
3. Hadoopの5つのメリット——なぜ大規模データ処理の標準になったのか
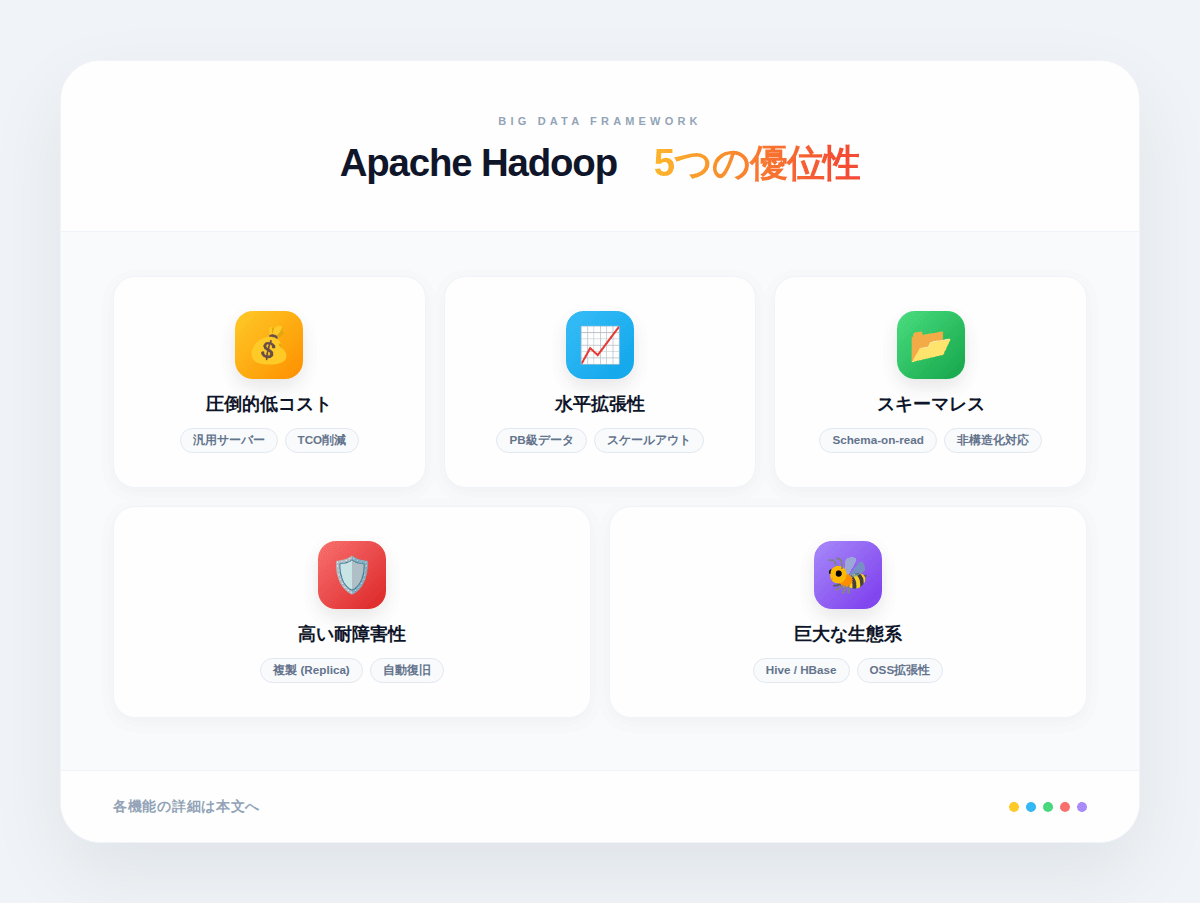
Hadoopが2000年代後半から2010年代にかけてビッグデータ処理の主流になった背景には、従来の技術では難しかった5つの優位性があります。
メリット①:コモディティサーバーで実現する低コストなHadoop導入
専用機器が不要なコスト構造
Hadoopの特徴のひとつが、高価な専用機器を必要とせず、コモディティサーバー(市販の汎用サーバー)でクラスターを組める点です。
従来の大規模データ処理では、Oracle ExadataやIBMのエンタープライズストレージなど、数千万〜数億円規模のハードウェアが必要でした。
廃棄型運用とTCO優位性
Hadoopなら1台数十万円程度のPCサーバーを多数並べるだけで同等以上の処理能力を発揮できます。
ノード1台あたりの単価が低いため、壊れたサーバーをそのまま交換する「廃棄型」の運用も十分現実的です。初期コストだけでなく、長期的な運用コスト(TCO)の面でも有利です。
メリット②:Hadoopが持つペタバイト規模のデータにも耐えるスケーラビリティ
スケールアウトによる柔軟な拡張
Hadoopは「スケールアウト(水平拡張)」の設計を採用しており、処理能力や容量が足りなくなったらサーバーを追加するだけで対応できます。
理論上は数千台規模のクラスターも組めるため、ペタバイト(1ペタバイト=約100万ギガバイト)を超えるデータでも扱えます。
グローバル企業の運用実績
「1台のサーバー性能を上げていく」方式では、ハードウェアの上限に達した時点でそれ以上の拡張が難しくなります。
Hadoopはデータが増えたときにサーバーを追加するだけで済むため、ビジネスの成長に合わせた柔軟な拡張が可能です。
実際にFacebookやYahoo!では、数千台規模のHadoopクラスターを長期にわたって運用した実績があります。
メリット③:非構造化データも扱えるHadoopのスキーマレス設計
Schema-on-writeとSchema-on-readの違い
従来のリレーショナルデータベース(RDBMS)はデータを格納する前にテーブルの列名やデータ型を厳密に定義する「Schema-on-write(書き込み時スキーマ定義)」方式です。
ログデータ・画像・音声・センサーデータのような非構造化データや半構造化データを大量に扱う際には不便です。
HDFSの柔軟な格納方式
一方のHadoop(HDFS)は「Schema-on-read(読み取り時スキーマ定義)」方式で、まずデータをそのまま格納し、読み込む際にスキーマを当てはめて解釈します。
フォーマットがバラバラなデータも一箇所に集めて分析できるため、多様なデータを扱う現場での使い勝手が高いです。
メリット④:HDFSのレプリケーションが支える高い耐障害性
自動複製による障害への備え
HDFSのレプリケーションにより、各データブロックが3つのノードに複製されます。1〜2台のサーバーが同時に壊れてもデータは失われず、処理を継続できます。
ハートビート監視による自律的なデータ復旧
NameNodeがすべてのノードの稼働状況を定期的に確認(ハートビート監視)しており、障害を検知すると自動でデータを別ノードへ再配布します。
手動で対応しなくてもデータが守られるため、大規模クラスターの安定運用に役立ちます。
メリット⑤:Apache Hadoopのオープンソース性が生む豊富なエコシステム
HadoopはApache License 2.0のもとで公開されており、ライセンス費用なしで使えます。
さらにHadoop本体と連携するサブプロジェクトが充実しているため、目的に応じた拡張が容易です。IBMの公式資料でも紹介されている主要なサブプロジェクトを以下にまとめます。
| プロジェクト名 | 主な用途 |
|---|---|
| Apache Hive | HadoopのデータにSQL類似言語(HiveQL)でクエリを発行 |
| Apache Pig | データフロー記述言語(Pig Latin)でETL処理を記述 |
| Apache Sqoop | RDBMSとHDFS間のデータ転送を効率化 |
| Apache HBase | HDFS上で動くNoSQL型のカラム指向データベース |
| Apache Flume | ログデータの収集・集約・転送 |
| Apache ZooKeeper | 分散システムの設定管理・ノード間の調整 |
(出典:Hadoopとは | IBM)
4. Hadoopの4つのデメリットと課題——Hadoop導入前に知っておくべき制約

Hadoopにはさまざまなメリットがある一方、技術的な制約や運用上の注意点もあります。導入を検討する前に、以下の4つの課題を把握しておきましょう。
課題①:Hadoopはバッチ処理前提のためリアルタイム処理には不向き
ディスク書き込みによる遅延の問題
Hadoopはもともとバッチ処理(データをまとめて一括処理する方式)向けに設計されています。
MapReduceは処理の各段階でデータをディスクに書き込むため、処理完了まで数十秒〜数分かかることがあります。
そのため、決済処理や不正検知アラート、株式取引などミリ秒単位の応答が求められる場面には向きません。
リアルタイム処理には別技術との組み合わせが必要
リアルタイム処理が必要な場合は、インメモリ処理で高速なApache Sparkや、ストリームデータをリアルタイムで処理できるApache Kafkaと組み合わせるのが一般的です。
Hadoopは大規模バッチ処理・長期データ保存の基盤として位置づけ、役割を分けることがポイントです。
課題②:Hadoopクラスターの管理には専門スキルが必要
Hadoopクラスターを安定して動かすには、ノード数やネットワーク構成の設計、メモリ配分やブロックサイズのチューニング、クラスターの死活監視、Kerberos認証の設定など、幅広い知識が必要です。
こうしたスキルを持つエンジニアは国内では少なく、採用が難しいという課題があります。
この問題を解決する現実的な方法として、AWS EMRやGoogle Cloud Dataprocといったクラウドマネージドサービスの利用が挙げられます。
クラスターの構築・スケーリング・パッチ適用をクラウド側が担ってくれるため、運用チームの負荷を大きく減らせます。
課題③:国内市場でHadoopスキルを持つ人材が希少
習得に必要なスキルの広さ
Hadoopを使いこなすには、Linuxの基礎、Javaプログラミング、分散システムの知識、クラスター設計など、複数の技術分野にわたるスキルが必要です。
日本国内でHadoopを実務レベルで扱えるエンジニアは少なく、採用コストが高くなりがちです。
中小組織での現実的な対策
自社でHadoopを運用しようとすると、採用・育成コストに加えてエンジニアの離職リスクも課題になります。
規模が小さい組織では、クラウドマネージドサービスへの移行で専門人材への依存を下げることが現実的な選択肢です。
課題④:Hadoopのデフォルト設定では不十分なセキュリティ対策
デフォルト設定のリスク
Hadoopはデフォルト設定のままでは、ユーザー認証や通信の暗号化が十分ではありません。
クラスター内の通信が暗号化されずに流れたり、なりすましによる不正アクセスのリスクが生じたりします。
本番運用に必要なセキュリティ設定
本番環境で安全に運用するには、Kerberos認証の導入、HDFSの通信暗号化(TLS/SSL)、Apache RangerやApache Knoxを使ったアクセス制御と監査ログの整備が必要です。
これらの設定には専門知識が必要で、「管理コストの高さ」とも直結する課題です。
(出典:Apache Hadoop とは | Google Cloud)
■日本でエンジニアとしてキャリアアップしたい方へ
海外エンジニア転職支援サービス『 Bloomtech Career 』にご相談ください。「英語OK」「ビザサポートあり」「高年収企業」など、外国人エンジニア向けの求人を多数掲載。専任のキャリアアドバイザーが、あなたのスキル・希望に合った最適な日本企業をご紹介します。
▼簡単・無料!30秒で登録完了!まずはお気軽にご連絡ください!
Bloomtech Careerに無料相談してみる
5. HadoopとApache Spark——使い分けと共存の実態

「Hadoopの時代は終わった」「SparkがHadoopを置き換えた」という声を耳にすることがありますが、これは正確ではありません。
現在の大規模データ処理の現場では、両者が役割を分担して共存するケースが多く、正しく理解したうえで技術を選ぶことが大切です。
SparkはHadoopの「後継」ではなく「補完技術」である
Sparkのインメモリ処理と高速性
Apache Sparkはカリフォルニア大学バークレー校のAMPLabで開発されたインメモリ型の分散処理フレームワークです。
処理データをメモリ(RAM)上に保持するため、機械学習や繰り返しデータを参照する分析では、MapReduceと比べて最大100倍以上の速度になるケースもあります。
HDFSを共有する補完関係
ただしSparkはあくまで「処理エンジン」です。大量データを長期間・低コストで保存するストレージ基盤としては、HadoopのHDFSが今も多くの現場で使われています。
「HDFSにデータを蓄積し、処理はSparkで行う」という組み合わせが現在の一般的な構成のひとつです。SparkはHadoopの「置き換え」ではなく、お互いを補い合う関係にあります。
用途別の選択基準——バッチ処理はHadoop、リアルタイム分析はSparkが優位
| 比較軸 | Hadoop(MapReduce) | Apache Spark |
|---|---|---|
| 処理方式 | ディスクベース(バッチ) | インメモリ(バッチ+ストリーム) |
| 処理速度 | 低〜中(ディスクI/Oがボトルネック) | 高速(メモリ上での繰り返し処理が得意) |
| コスト | ストレージ単価が低く大規模保存に有利 | 大容量メモリが必要なためサーバーコストが高め |
| 学習コスト | Java中心、設定が複雑 | Scala/Python/RのAPIが充実していて扱いやすい |
| 主なユースケース | 大規模ETL・ログ集計・バッチ集計 | 機械学習・リアルタイム分析・インタラクティブ分析 |
| リアルタイム性 | 不向き(バッチのみ) | Structured Streamingでストリーム処理に対応 |
| ストレージ | HDFS(内蔵) | HDFS・S3・GCSなど外部ストレージに依存 |
6. Hadoopの主な活用事例——金融・医療・製造・流通での実績

Hadoopは特定の業種に限らず、大量データを長期保存・バッチ処理する必要がある幅広い業界で使われています。代表的な4分野の活用事例を紹介します。
金融業界:Hadoopによる大量トランザクション分析と不正検知
膨大なトランザクションデータの活用
金融機関では、毎日数億件規模のカード決済・銀行振込・証券取引などのデータが発生します。
これをHadoopに集めて過去データと照らし合わせることで、不正利用の検知精度向上やマネーロンダリングの兆候把握に役立てています。
国内外の導入実績
JPMorgan ChaseなどがHadoopを採用したことで知られており、信用スコアリングモデルの学習データ蓄積にも使われています。
国内でも大手銀行が勘定系とは別のデータ分析基盤としてHadoopを導入した事例が報告されています。大量の履歴データを一括処理するバッチ分析は、Hadoopが最も力を発揮する領域のひとつです。
医療・ライフサイエンス:Hadoopを活用したペタバイト規模のゲノムデータ解析
ゲノム研究とデータ量の課題
ゲノミクス(遺伝子解析)の分野では、1人分のゲノムシーケンスデータだけで約200GB(圧縮前)にもなります。
数万人規模の研究になると、ペタバイト単位のデータを扱う必要があります。こうした大規模なデータの処理にHadoopは欠かせない基盤となっています。
医療・研究機関での活用例
海外の研究機関では、がんゲノム情報を大規模に解析してバイオマーカーを発見する研究や、新薬候補のスクリーニングにHadoopを活用した事例があります。
電子カルテデータ(EHR)の大規模分析にも使われており、疫学研究の効率化にも貢献しています。
流通・EC:Hadoopによるクリックストリーム分析とレコメンデーション最適化
クリックストリームデータの大規模処理
ECサイトや流通企業では、ユーザーがどのページを見てどの商品をカートに入れ、どこで離脱したかを記録したクリックストリームデータが大量に蓄積されます。
Hadoopはこの膨大なアクセスログをまとめて処理し、購買パターンの分析やレコメンデーションエンジンへの活用に使われています。
国内事例:アスクル株式会社
国内事例としては、アスクル株式会社がHadoopを導入して大規模なクリックストリーム分析と顧客行動のパーソナライズに活用していることが、Tableauの公式記事で紹介されています。
大量のログを低コストで長期保存しながら分析できる点がHadoopの強みです。
(出典:Hadoop とは? | Tableau)
製造業:Hadoopを用いたセンサーデータ処理とサプライチェーン最適化
センサーとSCMデータの集約
製造業では、生産ラインのセンサーが温度・振動・電流値などのデータを高頻度で送り続けます。また、仕入れ・在庫・出荷・物流に関するデータが多拠点・多システムにまたがって発生します。
これらをHadoopにまとめてバッチ処理することで、次のような活用が実現しています。
- 設備の異常を早めに検知して、突然の停止を減らす
- 不良品率を統計的に分析して製造プロセスを改善する
- 需要予測をもとに在庫を適正化して廃棄ロスを減らす
国内メーカーの導入実績
国内でも大手自動車メーカーや電機メーカーがHadoopをビッグデータ分析基盤として採用しており、NECも自社の活用事例を公開しています。
IoTデバイスの普及で製造現場のデータ量は増え続けており、大規模なストレージ基盤としてのHadoopのニーズは今後も続くとみられます。
(出典:Hadoop とは? | Tableau)
7. HadoopとクラウドサービスのAWS EMR・GCP Dataproc——オンプレとの違いを比較
Hadoopを実際に動かす方法は大きく2つあります。自社データセンターにサーバーを用意して構築する「オンプレミス」と、クラウド上でHadoopクラスターをマネージドサービスとして使う方式です。
それぞれのコスト・運用負荷・スケーラビリティを理解したうえで選ぶことが大切です。
AWS EMR・GCP DataprocでHadoopを使うとインフラ管理の負荷を大幅に削減できる
AWS EMR(Elastic MapReduce)の特徴
AWS EMRは、AmazonがマネージドサービスとしてHadoopクラスターを提供するサービスです。
数クリックでHadoop(HDFS・YARN)やApache Sparkを搭載したクラスターを起動でき、構築・設定・パッチ適用・スケーリングはAWSが担います。
コスト面では必要な時間だけクラスターを起動する従量課金モデルを採用しており、バッチ処理が終わったらクラスターを削除することで、使っていない時間のコストをゼロにすることもできます。
Amazon S3をHDFSの代わりに使えるため、ストレージと計算資源を切り離した柔軟な構成も実現できます。
(出典:Hadoop とは何か? | AWS)
GCP Dataproc(Google Cloud Dataproc)の特徴
Google Cloud DataprocはGCPが提供するマネージドHadoop/Sparkサービスです。
クラスターの起動が90秒以内と速く、処理が終わったらクラスターを削除してGoogle Cloud Storage(GCS)にデータだけ残す「使い捨てクラスター」のパターンが推奨されています。
BigQueryやCloud StorageなどほかのGCPサービスとの連携も簡単です。
(出典:Apache Hadoop とは | Google Cloud)
データガバナンスを重視する環境ではオンプレミスHadoopが依然有力な選択肢
クラウドマネージドサービスは便利ですが、オンプレミスでHadoopを維持した方がよいケースも存在します。主な理由は以下の通りです。
オンプレミスが向いているケース
規制・コンプライアンス上の制約:
金融機関の個人情報、医療機関の診療記録、公共インフラのデータなど、法令や業界規制によりデータをクラウド事業者に預けられないケース
長期的なコストの最適化:
クラスターを24時間365日常時稼働させるワークロードでは、従量課金より専有サーバーを購入・運用した方がコストを抑えられる場合がある
ネットワーク帯域の制約:
大量データを頻繁にクラウドへ転送するのが現実的でない環境では、データの近くで処理する方が効率的
どちらが向いているかは、データの機密性・常時稼働の必要性・運用チームのスキル・予算規模などを合わせて判断する必要があります。
8. Hadoopエンジニアの将来性と市場価値——データ人材の需要トレンドを読む

「Hadoopは古い技術では?」と感じているエンジニアもいるかもしれません。ここではビッグデータ市場の現状と、Hadoopスキルのキャリア上の価値について公的データをもとに整理します。
国内ビッグデータ市場はCAGR14.3%で拡大——データエンジニア需要は増加傾向
IDC Japanの調査によれば、国内のビッグデータ/アナリティクス市場は2027年までの年平均成長率(CAGR)が14.3%に達すると予測されています。
DX推進・IoTデバイスの普及・生成AIへのデータ供給需要の増大などを背景に、大量データを収集・蓄積・処理できる人材へのニーズは中長期的に高まっています。
経済産業省の「DXレポート」でも、データ活用を推進できる人材の不足が日本企業の課題として繰り返し指摘されており、データエンジニアリングスキルを持つエンジニアの市場価値は今後も高い水準が続く見込みです。
(出典:IDCが2024年の国内ビッグデータ/アナリティクス市場を予測 – CodeZine)
Hadoopは「過去の技術」ではなく大規模処理の「基盤技術」として今も現役
「SparkやクラウドDWHにHadoopが置き換えられた」という見方は部分的には正しいですが、全体像としては誤りです。Hadoopは今も多くの企業の本番環境で稼働しています。主な理由は以下の通りです。
- 数ペタバイト規模のデータをストレージコスト最小で保存するためにHDFSを使い続けている組織は多い
- 既存のHadoopベースのETLパイプラインをSparkやクラウドへ移行するには大きなコストと時間がかかるため、段階的な移行が続いている
- SparkもHDFSと組み合わせて動くケースが多く、HadoopのインフラはSparkを使うエンジニアにも必要な知識
Hadoopを「もう使われない技術」と判断するのは早計です。大規模分散処理の考え方や運用ノウハウは、データエンジニアとして働く上での基礎知識として今も価値があります。
Hadoopと組み合わせて習得したいスキルとキャリアパスの広げ方
推奨スキル習得ロードマップ
| フェーズ | 習得スキル | 目的 |
|---|---|---|
| 入門 | Linux基礎 / Python / SQL | データエンジニアリングの基礎を固める |
| 基礎 | HDFS・YARN・MapReduce / Apache Hive | Hadoopの仕組みと基本的なクエリ操作を習得 |
| 発展① | Apache Spark(PySpark) / Apache Kafka | 高速処理・ストリーム処理への対応力を身につける |
| 発展② | BigQuery / Amazon Redshift / Snowflake | クラウドDWHを使ったモダンなデータ処理に対応する |
| 応用 | MLflow / Airflow / dbt / Terraform | MLパイプライン・データオーケストレーションの自動化 |
キャリアパスの広がり
Hadoopをベースとした知識は、データエンジニアという職種にとどまらず、さまざまなキャリアに活かせます。
- MLエンジニア(機械学習モデルのデータ基盤構築)
- データアーキテクト(データ基盤全体の設計)
- クラウドインフラエンジニア(AWS/GCP上のデータ基盤運用)
など、データを軸に動く組織で需要の高い職種へのキャリアチェンジにも役立ちます。
特にSparkとHadoopの両方を理解しているエンジニアは、大規模データ基盤の設計・移行プロジェクトで希少価値が高く、転職市場でも評価されやすい傾向があります。
9. まとめ:Hadoopとは、ビッグデータ時代を支えるエンジニア必須の分散処理基盤

Hadoopとは、HDFS(分散ストレージ)・MapReduce(分散処理)・YARN(リソース管理)の3つが連携する分散処理基盤です。
低コスト・高いスケーラビリティ・耐障害性が強みで、一方でリアルタイム処理への対応や運用の複雑さに課題もあります。
Sparkやクラウドサービスとは補完関係にあり、データエンジニアリングの基礎技術として今も現役です。
IDCが示す国内ビッグデータ市場のCAGR14.3%の成長を背景に、Hadoopスキルを起点にしたデータエンジニアへのキャリアは中長期的に有望です。
















