データエンジニアへの転職・キャリアアップを目指すITエンジニアに向けて、求められるスキルセットの全体像を7つの領域に整理して解説します。
IPA・厚生労働省などの公的機関データをもとに、プログラミングからクラウド基盤、生成AI対応まで網羅しています。
自身の現在地を確認しながら、スキル習得の優先順位を明確にできる内容となっています。
- データエンジニアに必要なスキルセットの7領域と優先順位について
- ITSSレベル別の年収目安とキャリアパスの全体像について
- 生成AI・AIガバナンスなど最新トレンドへの対応スキルについて

1. データエンジニアスキルセットの全体像|定義と7領域の位置づけを理解する

データエンジニアに求められるスキルは多岐にわたります。まずは職種の定義と、スキル全体の構造を整理しましょう。
データエンジニアの定義は「データの動脈を設計・運用する職種」
データエンジニアとは、組織が持つ大量のデータを収集・変換・格納し、分析や意思決定に使える状態に整備するための基盤を設計・運用する職種です。
厚生労働省の職業情報提供サイト(job tag)では「ビッグデータエンジニア」とも呼ばれ、「その他の情報処理・通信技術者(ソフトウェア開発を除く)」に分類されています。
主な業務は、情報の文書化・記録・仕様設定・図面作成など、データの流通と品質管理全般です。
「ITSSプラス」での定義
IPA(独立行政法人情報処理推進機構)が策定する「ITSSプラス」では、データ活用に必要なスキルを「ビジネス力」「データサイエンス力」「データエンジニアリング力」の3つで定義しています。
データエンジニアリング力は、データの収集・加工・蓄積・配信を行うシステム全体を設計・実装・運用する能力です。データサイエンティストの分析を支える「情報の動脈」を担う役割といえます。
データサイエンティストが統計や機械学習を使って知見を引き出すのに対し、データエンジニアはその分析が安定して継続できるデータ基盤そのものを作る役割を担います。両者は競合ではなく、お互いを補い合う関係です。
出典:厚生労働省「職業情報提供サイト(job tag)データエンジニア職業詳細」 / IPA「ITSSプラス データサイエンス領域スキルチェックリスト概説」
スキルセットは技術・ガバナンス・ビジネス理解の3層構造で成り立っている
データエンジニアのスキルセットは、「技術基盤層」「データ管理層」「応用・連携層」という3つの層に整理できます。
3層構造の概要
- 技術基盤層:プログラミング言語・データベース設計・ETLパイプライン・クラウド/分散処理基盤
- データ管理層:データ品質管理・データガバナンス・セキュリティ・コンプライアンス対応
- 応用・連携層:生成AI活用・AIガバナンス・ソフトスキル・ビジネス理解
技術基盤層はまず最優先で習得すべき領域です。データ管理層はシステムの信頼性を支える領域で、上位職になるほど比重が増します。
応用・連携層は技術力をビジネス価値につなげる能力群で、キャリアの分岐点で差が出やすい部分です。
2. データエンジニアスキルセット①|プログラミング言語の習熟が技術力の土台になる
プログラミング言語の習熟は、データエンジニアとしての実務をこなすための出発点です。どの言語をどの順番で習得すべきか、用途とともに整理します。
Pythonは汎用性最高、JavaとScalaは大規模処理で真価を発揮する
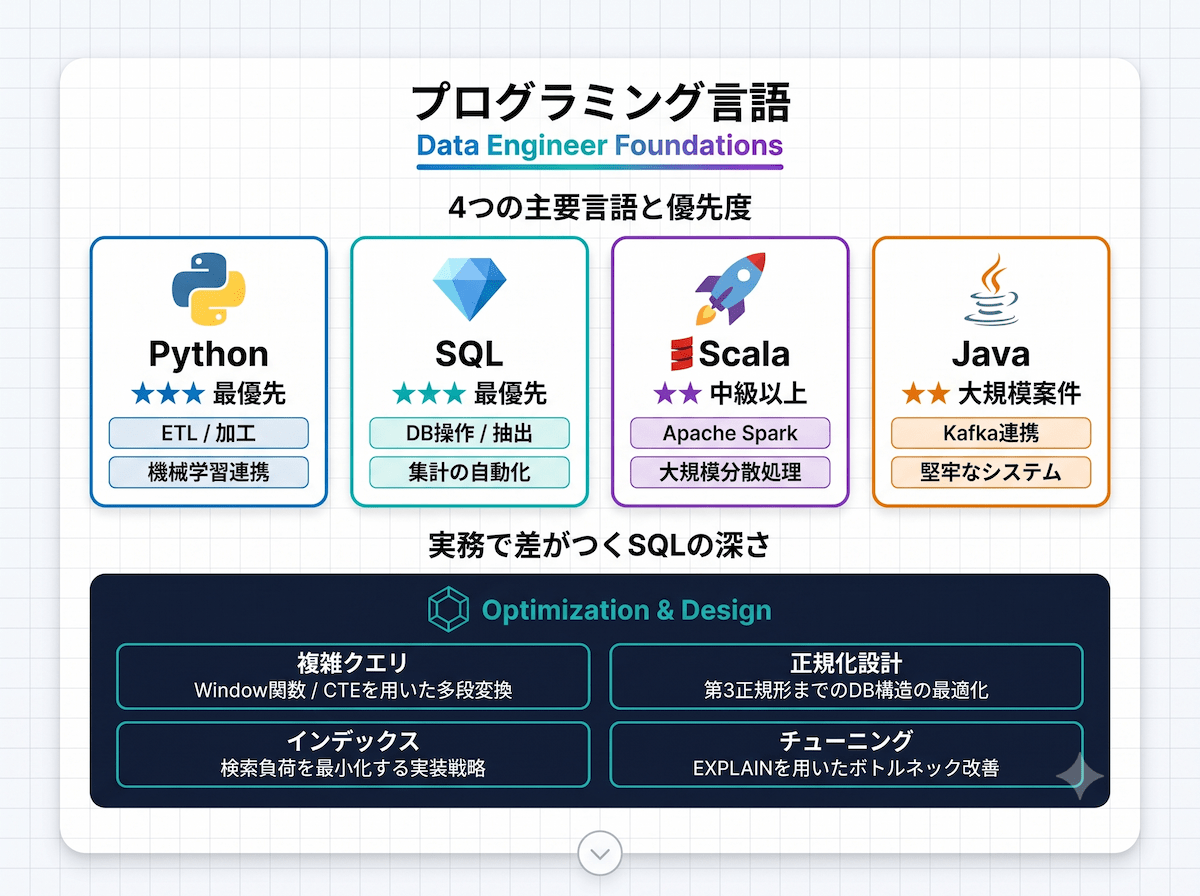
データエンジニアが扱う主な言語は、Python・Java・Scala・SQLの4つです。
それぞれ得意な用途が異なるため、携わるシステムの規模や役割に合わせて習得を進めましょう。
言語別の用途と優先度
| 言語 | 主な用途 | 習得優先度 |
|---|---|---|
| Python | データ加工・ETL処理・機械学習連携・スクリプト全般 | ★★★(最優先) |
| SQL | DB操作・クエリ最適化・データ抽出・集計処理 | ★★★(最優先) |
| Scala | Apache Spark連携・大規模分散処理・ストリーム処理 | ★★(中級以上で必要) |
| Java | 大規模バックエンド・堅牢なシステム構築・Kafka連携 | ★★(大規模案件で有効) |
PythonはpandasやNumPyといったデータ処理ライブラリが豊富なため、最初に習得すべき言語です。
コードが書けるだけでなく、パフォーマンスの最適化・エラー処理・モジュール設計まで含めた実務レベルの習熟が求められます。
JavaやScalaは大規模な分散処理基盤で強みを発揮し、Apache SparkやApache Kafkaを使うプロジェクトでは欠かせません。
SQLは読み書きだけでなく「設計・最適化」まで求められる
SQLはデータエンジニアが最も頻繁に使う言語のひとつです。単純なデータ取得にとどまらず、設計や最適化まで含めた深い活用が実務では求められます。
実務で求められるSQLスキルの深さ
- 複雑クエリの構築:サブクエリ・ウィンドウ関数・CTEを使った多段階の集計・変換処理
- 正規化設計:データの重複排除・更新エラーの防止を目的とした第1〜第3正規形への対応
- インデックス設計:検索パフォーマンスを左右するインデックス戦略の立案と実装
- クエリ最適化:実行プラン(EXPLAIN)を読み解き、ボトルネックを特定して改善する
クラウド型DWH環境では、BigQueryやSnowflakeに特有のSQL操作も必要です。
クエリコストの最適化はインフラコストに直結するため、DWH固有のチューニング知識はミドル以上のデータエンジニアに期待されるスキルといえます。
3. データエンジニアスキルセット②|データベース設計とモデリングがシステムの価値を左右する
データベース設計の良し悪しは、システム全体の品質と将来の拡張性に直接影響します。
RDBを中心に、NoSQLやクラウドDWHまでの設計スキルを確認しましょう。
RDBの論理設計力がデータ整合性と拡張性の土台になる
RDB(リレーショナルデータベース)を適切に設計するには、概念設計・論理設計・物理設計の3段階を正しく進める能力が必要です。
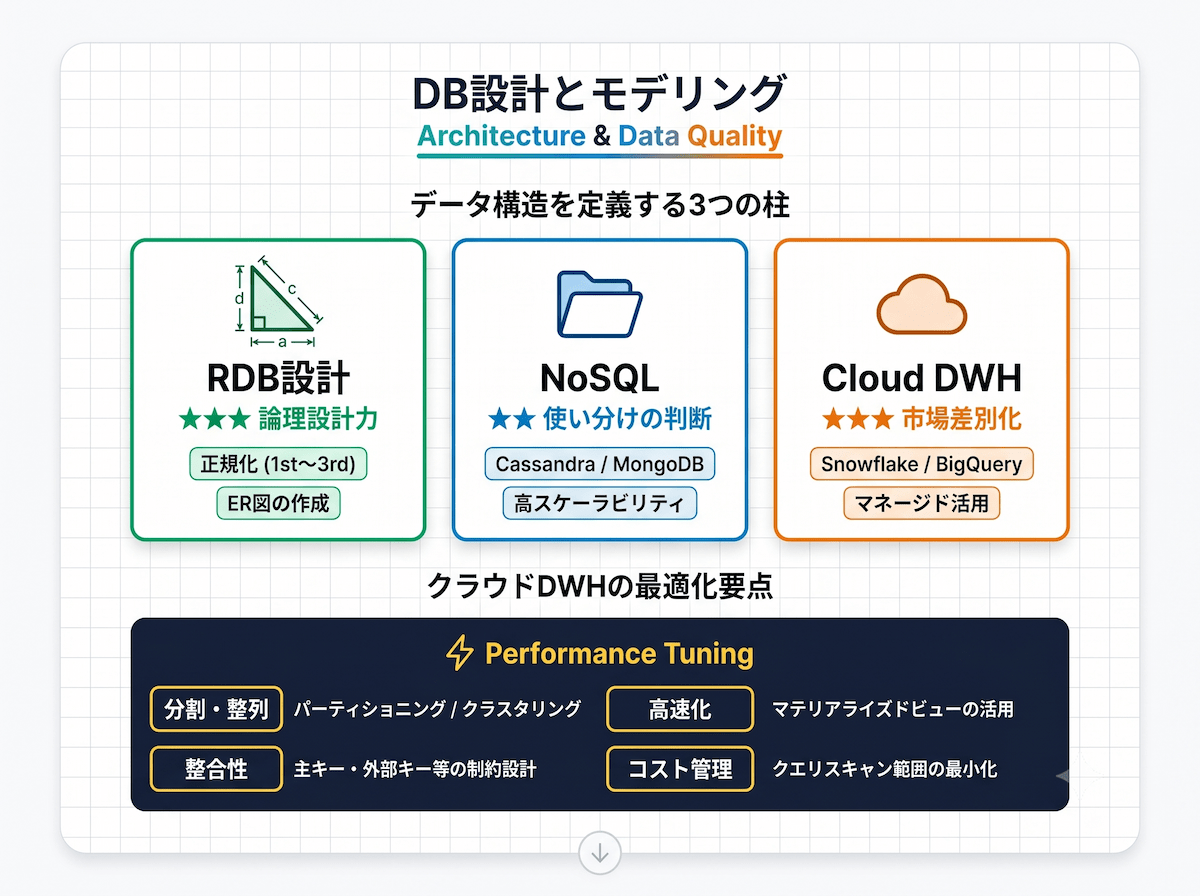
RDB設計に求められる知識領域
- ER図の作成:エンティティ・リレーションシップ図でデータ構造を見える化し、関係者と認識を合わせる
- 正規化理論の適用:データの重複排除や更新エラーを防ぐため、第1〜第3正規形(必要に応じてBCNF)に対応する
- 整合性制約の設計:主キー・外部キー・NOT NULL・一意性制約を使ってデータ品質を守る
設計が不十分だと、システムの拡張時にテーブル構造を大きく作り直す必要が生じ、コスト増や障害リスクにつながります。論理設計力は中途採用でも確認されることが多い、基本的かつ重要なスキルです。
NoSQLデータベース(Cassandra・MongoDB等)は、大量の非構造化データや高速な書き込みが必要な場面で有効です。
RDBとの使い分けは、データの一貫性要件・スケーラビリティ・クエリのパターンという3つの軸で判断するとシンプルです。
クラウド型DWH(Snowflake・BigQuery)の最適化スキルは市場差別化になる
近年のデータ基盤では、クラウド型DWH(データウェアハウス)の活用が当たり前になっています。
SnowflakeやGoogle BigQueryはペタバイト規模のデータを高速処理できるマネージドサービスで、インフラ管理のコストを大きく削減できます。
クラウドDWHのパフォーマンスチューニング要点
- パーティショニング設計:日付やカテゴリでデータを分割し、クエリのスキャン範囲を絞り込む
- クラスタリング設定:よく使うフィルタ列を基準にデータを並べ替え、検索効率を上げる
- マテリアライズドビューの活用:集計結果をあらかじめ保存しておき、繰り返し処理のコストを下げる
- クエリコストの管理:BigQueryのスキャンバイト数課金の仕組みを理解した上でコストを最適化する
クラウドDWHの最適化スキルはランニングコストに直結するため、ビジネスへのインパクトが大きい領域です。実装できるエンジニアは採用市場でも差別化できます。
4. データエンジニアスキルセット③|ETLパイプライン構築がデータ活用の中核を担う
ETLパイプラインの構築は、データエンジニアの仕事の中で最も中心的な技術です。使われるツールの役割と、設計上の重要な考え方を押さえましょう。
Apache Airflowによるワークフロー管理は実務の必須技術
ETL(Extract・Transform・Load)とは、データをソースから取り出し(Extract)、分析に使いやすい形に変換し(Transform)、DWHやデータレイクに格納する(Load)一連の処理です
この流れを自動化・管理するツールとして、以下の3つが実務でよく使われます。
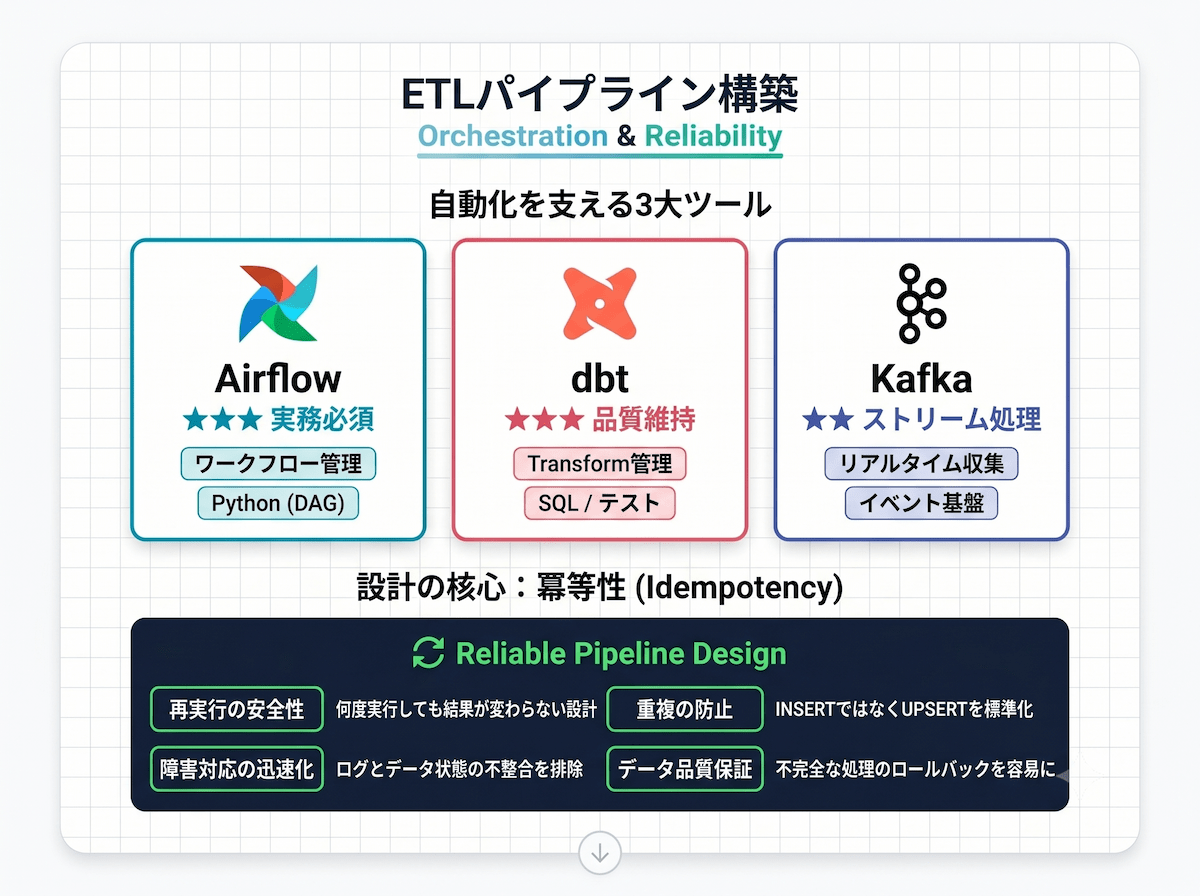
主要ツールの役割分担
| ツール名 | 役割 | 主な用途 |
|---|---|---|
| Apache Airflow | ワークフロー管理・スケジューリング | 処理ジョブの依存関係管理・自動実行・エラー通知 |
| dbt(data build tool) | Transform層の管理・テスト | SQLベースの変換ロジック管理・ドキュメント化・品質テスト |
| Apache Kafka | リアルタイムストリーム処理 | 大量イベントデータのリアルタイム収集・転送・処理 |
Apache AirflowはPythonでジョブの依存関係(DAG)を定義し、自動実行・監視・リトライを実現するツールです。PythonスキルとセットでDAGを書けるようになることが実務では基本となります。
dbtはSQL中心の変換ロジックをコードで管理し、テストやドキュメント化も一括して行えるため、データ品質の維持に役立ちます。
「冪等性(べきとうせい)」の設計がプロとアマを分ける
ETLパイプラインの設計で実務経験の有無が最もはっきり出るのが、「冪等性(idempotency)」という考え方です。冪等性とは、同じ処理を何度繰り返しても同じ結果になる性質を指します。
冪等性が重要な理由
- 障害時の再実行が安全:ネットワーク障害などでパイプラインが止まっても、再実行でデータの重複や欠損が起きない設計が必要です
- データ不整合を防ぐ:INSERTではなくUPSERT(INSERT OR UPDATE)を使うことで、二重実行時の重複を防げます
- 原因の特定がしやすい:べき等な処理はログと結果の対応が明確なため、障害発生時の調査がスムーズになります
冪等性を考慮しないパイプラインは、本番運用でデータ品質の問題を引き起こすリスクがあります。
採用面接でも「障害時の再実行設計をどう考えるか」という問いはよく出るため、具体的な経験とセットで説明できると大きなアピールになります。
■日本でエンジニアとしてキャリアアップしたい方へ
海外エンジニア転職支援サービス『 Bloomtech Career 』にご相談ください。「英語OK」「ビザサポートあり」「高年収企業」など、外国人エンジニア向けの求人を多数掲載。専任のキャリアアドバイザーが、あなたのスキル・希望に合った最適な日本企業をご紹介します。
▼簡単・無料!30秒で登録完了!まずはお気軽にご連絡ください!
Bloomtech Careerに無料相談してみる
5. データエンジニアスキルセット④|クラウドと分散処理基盤の習熟が現代の必須条件
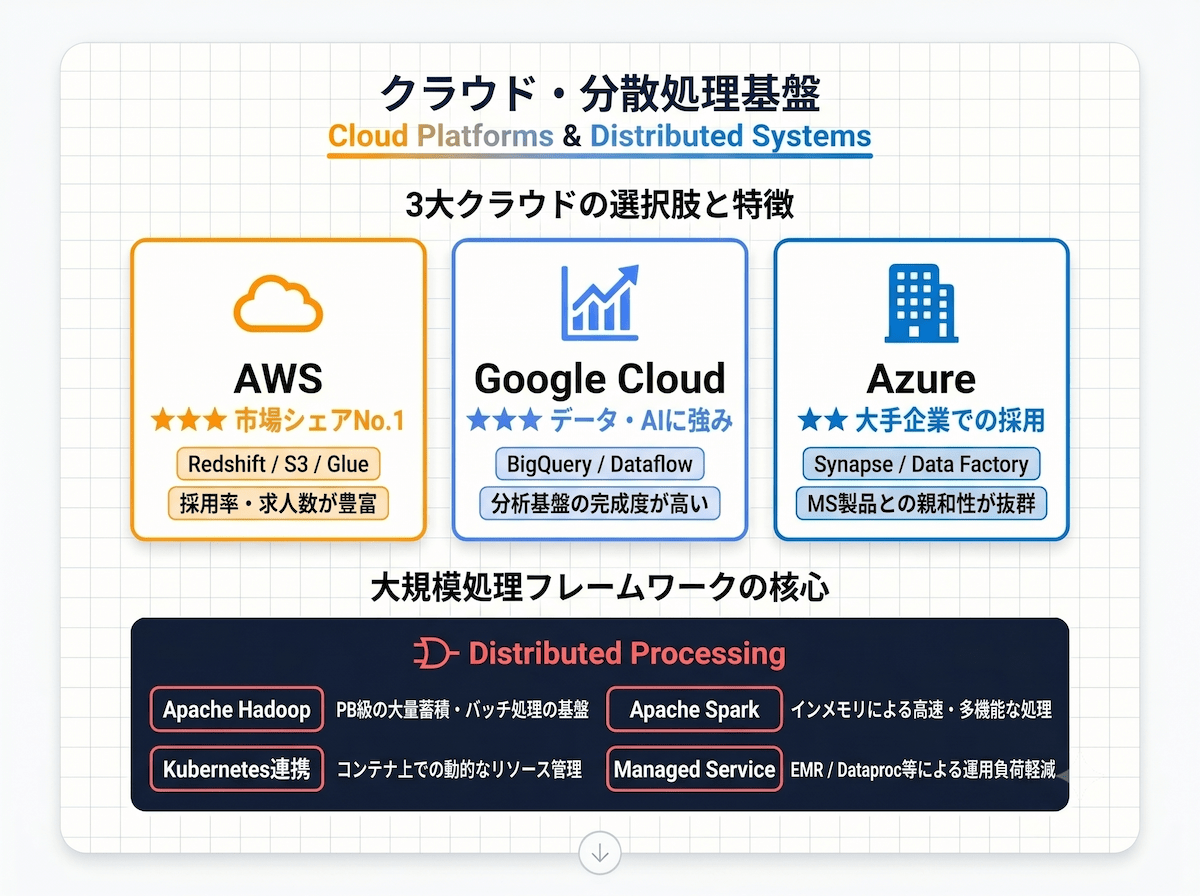
現代のデータ基盤はクラウド上に構築されるケースがほとんどです。主要な3大クラウドの特徴と、大規模処理に必要な分散処理フレームワークについて整理します。
AWS・GCP・Azureの3大プラットフォームは最低1つを深く習熟する
AWS・Google Cloud(GCP)・Microsoft Azureのいずれかへの習熟は、データエンジニアとして事実上の必須条件となっています。各クラウドが提供するデータ関連サービスは以下のとおりです。
3大クラウドのデータ関連サービス比較
| クラウド | DWHサービス | ETL/パイプライン | ストリーム処理 | データレイク |
|---|---|---|---|---|
| AWS | Amazon Redshift | AWS Glue | Amazon Kinesis | Amazon S3 |
| GCP | BigQuery | Cloud Dataflow | Pub/Sub | Cloud Storage |
| Azure | Azure Synapse | Azure Data Factory | Event Hubs | Azure Data Lake |
どのクラウドから学ぶべきか
- AWSを優先すべきケース:国内のIT企業・スタートアップでの採用率が最も高く、求人数も豊富です。クラウドを初めて学ぶ場合の第一候補です
- GCPを優先すべきケース:BigQueryやVertex AIなどデータ・AI系サービスの完成度が高く、データエンジニア・MLエンジニア志望に特に向いています
- Azureを優先すべきケース:金融・製造業など大手企業での採用率が高く、Microsoft製品との親和性を活かしたい場合に適しています
複数のクラウドを浅く触るより、1つを深く習熟するほうがキャリア初期には有効です。認定資格の取得を目標にすることで、学習が体系的に進みます。
Apache HadoopとSparkは大規模システムで高い市場価値を持つ
テラバイト・ペタバイト規模のデータを扱う大規模システムでは、分散処理フレームワークのスキルが高く評価されます。
主要分散処理フレームワークの概要
- Apache Hadoop:HDFS(分散ファイルシステム)とMapReduceによるバッチ処理が基盤です。大量データの蓄積と分散処理の基本概念を理解するうえで重要なフレームワークです
- Apache Spark:インメモリ処理でHadoopより高速な処理を実現します。バッチ・ストリーム・機械学習・グラフ処理をまとめてサポートしており、現在最も広く使われている分散処理エンジンです
近年はSparkをKubernetes上で動かす構成が増えており、コンテナ管理の基礎知識(Pod・Deployment・リソース制限等)も求められるケースが増えています。
AWS EMRやGCP Dataprocなどのマネージドサービスを使った実装経験は、採用評価でプラスになります。
6. データエンジニアスキルセット⑤|データ品質管理とガバナンスが企業信頼に直結する
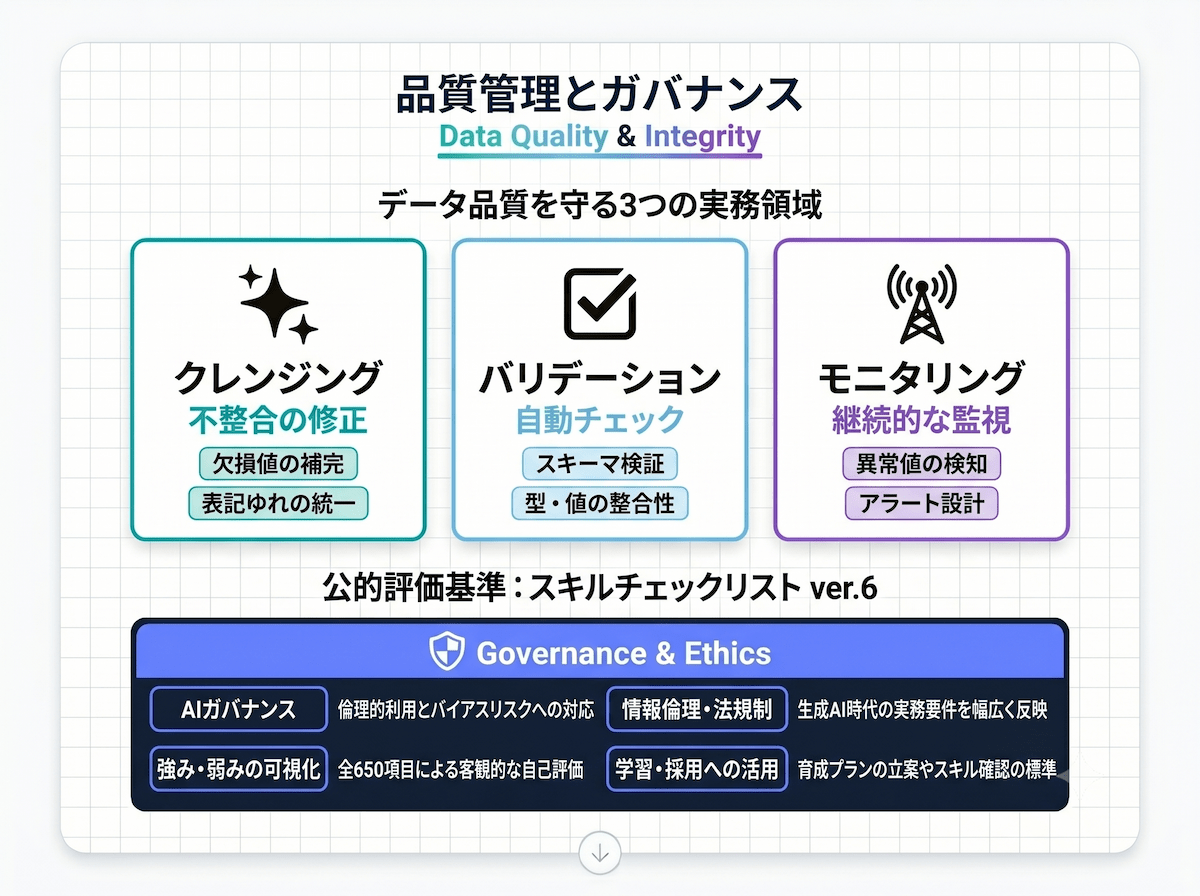
データ品質の管理は見落とされがちですが、組織がデータを使って正しい判断を下すための土台です。実務での対応内容と、スキル評価に使える公的ツールを確認しましょう。
データ品質の担保はデータエンジニアの責任範囲に含まれる
品質の低いデータをもとにした意思決定は、事業上の損失や信用の低下に直結します。データエンジニアはパイプラインを作るだけでなく、データ品質を守る仕組みを最初から組み込む責任を担っています。
データ品質管理の主要な実務領域
- データクレンジング:欠損値の補完・外れ値の検出・表記ゆれの統一・重複レコードの削除など、ソースデータの不整合を修正するプロセスです
- バリデーション(検証):入力データがスキーマ・型・値の範囲・参照整合性を満たしているかをパイプライン内で自動チェックする仕組みを作ります
- データモニタリング:データ量・更新頻度・異常値の発生などを継続的に監視し、品質の低下を早めに検知するアラートを設計します
dbtのテスト機能やGreat Expectationsなどのフレームワークを使えば、品質管理をコードとして管理(Data Quality as Code)できます。パイプラインの上流で品質を確保することがデータエンジニアの主な役割です。
データサイエンティスト協会のスキルチェックリスト(最新版)が自己評価の基準になる
一般社団法人データサイエンティスト協会は、データ活用人材のスキルを体系的に評価するための「スキルチェックリスト」を定期的に改訂・公開しています。
最新のver.6(2025年度版)は全650項目で、データエンジニアリングに関連する領域も幅広くカバーされています。
スキルチェックリスト ver.6の特徴
- AIガバナンス・情報倫理の項目が追加:AIの倫理的な使い方・バイアスリスクへの対応・法規制の理解に関する項目が新たに加わり、生成AI時代の実務要件を反映しています
- 自己評価ツールとして使える:650項目を5段階で自己評価することで、強み・弱みを見える化し、学習プランの立案に役立てられます
- 採用・育成にも活用できる:採用時のスキル確認や、メンバーの育成プランづくりにも使われています
ETLツールの操作・分散処理基盤の設計・データモデリングといったデータエンジニアリング領域の項目もチェックリストに含まれています。
3〜6ヶ月ごとに自己評価するサイクルを習慣にすることをおすすめします。
出典:データサイエンティスト協会「2025年度版データサイエンティスト スキルチェックリストver.6」
7. データエンジニアスキルセット⑥|生成AI・AIガバナンス対応が最新の差別化要因になっている
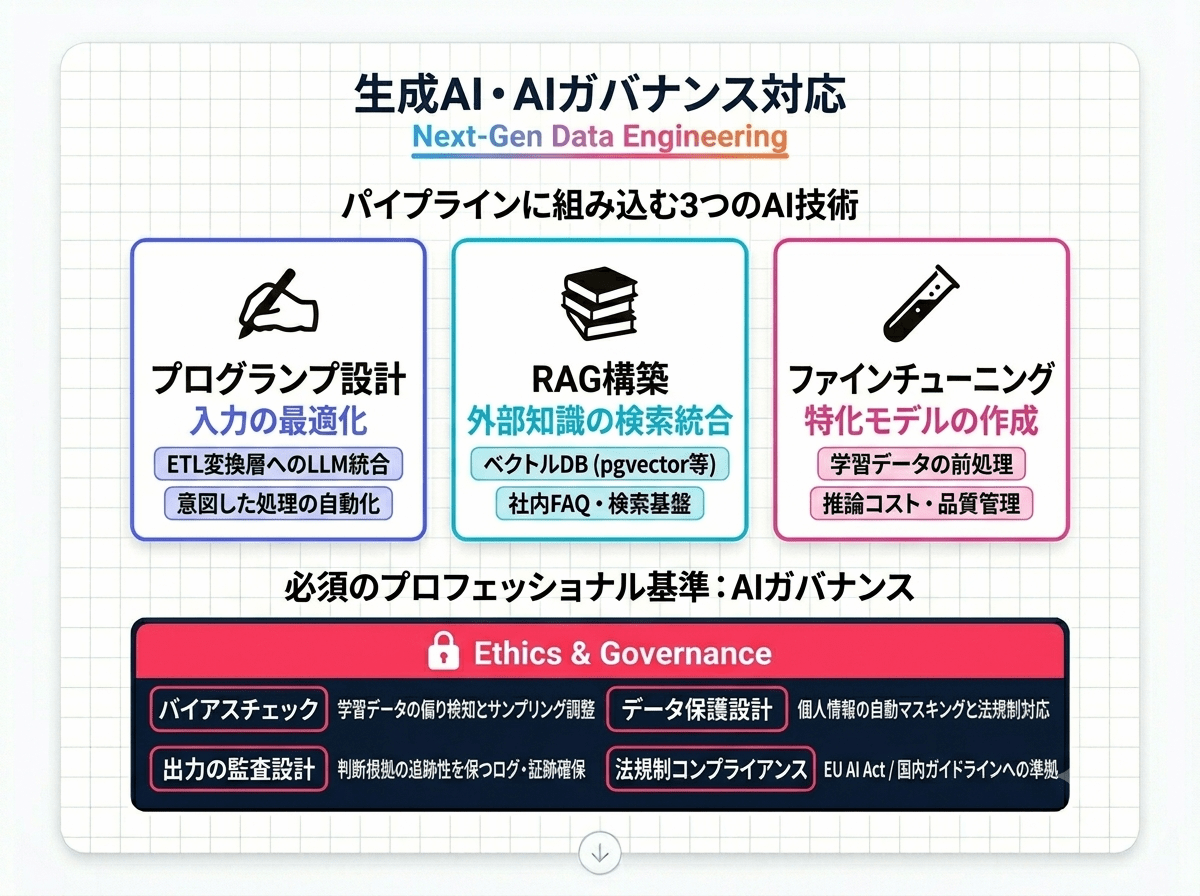
生成AIの普及に伴い、データエンジニアの仕事にもAI技術を組み込む場面が増えています。技術面の実装スキルと、倫理・ガバナンスへの対応力の両方が求められます。
プロンプト設計・RAG・ファインチューニングがデータ基盤構築に組み込まれている
従来のデータパイプラインにAIコンポーネントを組み込む実装スキルは、採用市場での評価が高まっています。主な技術と実務でのユースケースを確認しましょう。
データパイプラインへの生成AI統合:主要技術と実務ユースケース
プロンプト設計(Prompt Engineering):
LLM(大規模言語モデル)に意図した処理をさせるための入力設計です。ETLの変換(Transform)層にLLMを組み込む際に必要となります
RAG(Retrieval-Augmented Generation):
外部の知識ベースやデータベースから関連情報を取り出し、LLMの生成に組み合わせる手法です。
社内ドキュメント検索・FAQ自動応答・レポート生成などとデータパイプラインをつなぐ設計がデータエンジニアの担当領域となります
ファインチューニング(Fine-tuning):
自社データを使ってLLMを追加学習させることです。データの収集・前処理・学習データ管理といった工程でデータエンジニアが深く関わります
これらをパイプラインに組み込むには、ベクトルデータベース(Pinecone・Weaviate・pgvector等)の操作、LLM APIとのインターフェース設計、推論コストの管理といった新しい知識が必要です。
データエンジニアとMLエンジニアの境界が広がっており、両方をつなげる人材へのニーズが高まっています。
AIバイアスへの対応とデータ倫理がプロフェッショナルの条件になっている
生成AIをデータ基盤に組み込む際は、技術的な実装力と同時に、AIガバナンスと倫理への理解も必要です。
EU AI Actをはじめとした法規制の整備が世界的に進んでおり、日本でも内閣府の「AI戦略会議」が示すガイドラインへの対応が企業に求められています。
データエンジニアに求められるAI倫理対応の具体的な場面
学習データのバイアスチェック:
モデルの学習データに性別・人種・年齢などの偏りが含まれていないかを確認し、必要に応じてサンプリング比率の調整やデータの拡張を行います
個人情報・機密情報の管理:
LLMへの入力データに個人情報が含まれないようマスキング処理を施す設計が必要です。GDPRや個人情報保護法への対応も含まれます
モデル出力の監査設計:
LLMの判断・推奨の根拠を後から追跡できる状態に保つためのログ設計・監査証跡の確保を行います
「AIの問題をどう防ぐか」という問いに技術・倫理の両面から答えられるデータエンジニアは、AI活用プロジェクトでリーダー的な役割を担えます。
8. データエンジニアスキルセット⑦|ソフトスキルとビジネス理解が技術力を活かす鍵になる
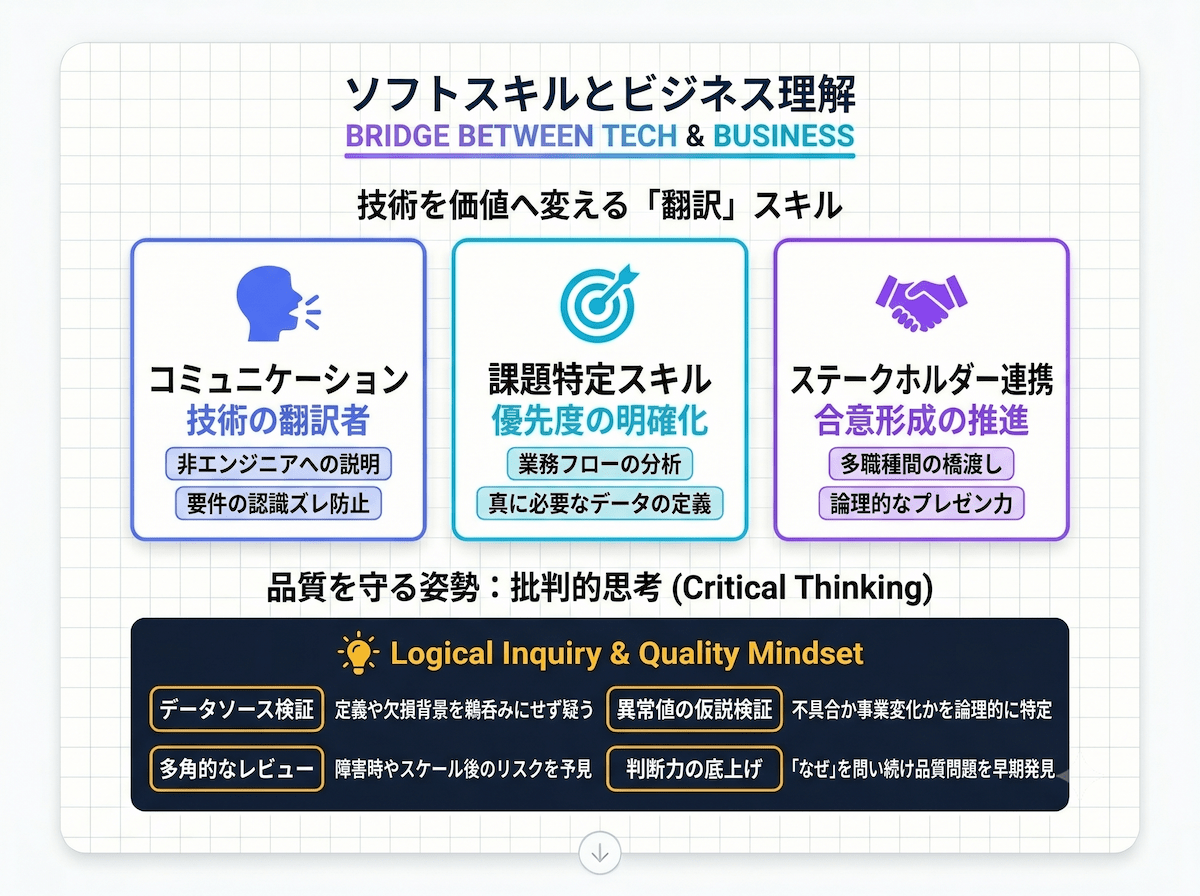
技術力が高くても、ビジネスの要件を正確につかんでシステムに落とし込む力がなければ、組織への貢献は限られます。
データエンジニアに求められるソフトスキルを確認しましょう。
技術仕様とビジネス要件を双方向に翻訳できる人材が求められている
データエンジニアは「技術の翻訳者」としての役割も担います。技術的な深さと同じくらい、ビジネスサイドとのコミュニケーション能力が重要です。
ビジネス連携を支えるソフトスキルの実務的な重要性
コミュニケーション能力:
経営層・マーケティング・営業など技術に詳しくない人たちに、データ基盤の仕組みや制約をわかりやすく伝える力です。要件定義での認識のズレを防ぐうえで欠かせません
課題特定スキル:
「どのデータが必要か」「どこに問題があるか」を業務フローの観点から分析し、優先度の高い課題をはっきりさせる力です
ステークホルダー連携:
データサイエンティスト・バックエンドエンジニア・インフラチーム・セキュリティ担当など多くの職種と協力しながら、進捗管理と合意形成を進める力です
中規模以上のプロジェクトでは、データエンジニアがテクニカルリードとしてアーキテクチャ設計の最終判断を担う場面もあります。技術的な意思決定を論理的に説明・説得できるプレゼン力も評価されます。
批判的思考(クリティカルシンキング)がデータ品質を守る精神的基盤になる
データエンジニアにとってクリティカルシンキングは、高品質なデータ基盤を作り続けるための基本姿勢です。
届いたデータをそのまま信頼せず、「このデータは本当に正しいか」「欠損の背景に何があるか」と問い続けることが、品質問題の早期発見につながります。
クリティカルシンキングが活きる実務場面
データソースの検証:
新しいデータソースを取り込む際に、収集方法・定義・更新頻度・欠損のパターンをしっかり確認し、下流の分析への影響を事前に評価します
異常値の仮説検証:
数値が突然増えたり減ったりした場合、システムの問題なのか事業上の変化なのかを仮説を立てて確かめます
設計レビューでの多角的な視点:
「障害が起きたらどうなるか」「半年後にスケールしたらどうなるか」という観点で自分の設計を見直し、リスクを洗い出します
クリティカルシンキングは習得に時間がかかりますが、実務を通じて意識的に磨くことで、データエンジニアとしての判断力全体を底上げできます。
9. データエンジニアのスキルセットと年収・市場価値|ITSSレベル別に見る報酬水準

データエンジニアの年収は、スキルレベルや市場の需給バランスによって大きく変わります。公的なスキル標準と転職市場のデータをもとに、報酬水準と需給動向を整理します。
平均年収は約530〜558万円でエンジニア全体平均を上回る水準にある
各種調査によれば、データエンジニアの平均年収は約530〜558万円です。ITエンジニア全体の平均(約540万円)と比べても同等以上の水準で、専門性の高さが報酬に反映されています。
フリーランス市場では平均月額単価が72万円(年収換算864万円)に達しており、スキル次第では月額175万円(年収換算2,100万円)超の案件も存在します。
スキルの習熟度でアウトプットの質が大きく変わる職種であることが、この報酬の幅に表れています。
ITSSレベル5以上では年収600〜950万円に達するスキルが求められる
経済産業省が策定したITスキル標準(ITSS)は、ITプロのスキルレベルを1〜7段階で定義するフレームワークです。データエンジニアの年収はこのITSSレベルと強く連動しています。
ITSSレベル別の年収目安
| ITSSレベル | スキル水準 | 想定年収範囲 |
|---|---|---|
| レベル5以上 | 業界をリードする卓越した専門性 | 600〜950万円 |
| レベル4 | 高度な専門スキル・独力での問題解決 | 500〜780万円 |
| レベル3 | 応用知識・標準業務の完遂 | 450〜700万円 |
| レベル1〜2 | 基本知識・指導下での業務遂行 | 420〜620万円 |
レベル5以上に到達するには、大規模データ基盤のアーキテクチャ設計をリードした実績や、複数のクラウド・分散処理環境を横断する高度な設計・実装経験が求められます。
資格取得・プロジェクト実績・自己評価を組み合わせながら、定期的にレベルアップを意識することが大切です。
転職市場ではデータエンジニア関連職種の登録者数が前年比118%まで増加している
dodaの中途採用マーケットレポートによれば、データエンジニア関連職種の登録者数は前年比で約114〜118%の伸びを示しています。
より良い条件を求める転職希望者が増えていることがわかります。
一方、有効求人倍率は1.6倍以上の高水準で推移しており、企業側の採用ニーズも旺盛です。情報通信業の離職率は8.1%と全産業平均(13.3%)を大きく下回っており、現職にとどまるエンジニアが多いことが求職者数を抑えています
。この需給ギャップが、データエンジニアの報酬水準を高く保つ背景となっています。
出典:doda「ITエンジニア中途採用マーケットレポート(2025年3月発行)」 / doda「ITエンジニア中途採用マーケットレポート(2025年6月発行)」
10. データエンジニアのスキル習得ロードマップとキャリアパス|段階別に進める方法

スキルをどの順番で、どのように習得すればよいかは、多くのエンジニアが悩むポイントです。入門から実務、上位職へのステップを段階別に整理します。
入門段階はPythonとSQLの習得とクラウド基礎から始める
データエンジニアへの第一歩は、ITSSレベル1〜2相当のスキルを実務水準まで確実に身につけることです。幅広く浅く触れるよりも、基礎をしっかり固めることを優先しましょう。
入門段階の学習ステップ
- ステップ1:
Python基礎の習得:構文・関数・クラスを理解した上で、pandas・NumPyを使ったデータ操作を実習します。Jupyter Notebookを活用した実験的な学習環境を作るのも効果的です - ステップ2:
SQL基礎〜中級の習得:SELECT・JOIN・集計関数・サブクエリを使った実践的なクエリ作成を習得します。SQLite・MySQLなどの無料環境での演習が有効です - ステップ3:
クラウド基礎の学習:AWS・GCP・Azureのいずれか1つを選び、無料枠を使ってストレージ・データベース・ETLサービスの基本操作を体験します - ステップ4:
公的学習リソースの活用:経済産業省・IPA運営の「マナビDX」では、デジタル人材育成のための講座コンテンツが整備されており、無料または低コストで体系的に学べます
出典:マナビDX(経済産業省・IPA)https://manabi-dx.ipa.go.jp/
実務参画後はETLとデータ基盤設計の経験を積んでレベル3〜4を目指す
実務に入ったら、学習だけでは得られない「本番データへの向き合い方」と「設計の実装責任」を通じてスキルを深めていく段階です。ITSSレベル3〜4の認定には具体的なアウトプット実績が必要になります。
実務段階で評価される具体的なアウトプット例
- Apache Airflowを使った本番ETLパイプラインの設計・構築・保守
- BigQueryまたはRedshiftでのDWHスキーマ設計とクエリ最適化の実施
- dbtを使ったデータ変換ロジックのコード管理とテスト自動化
- データ品質モニタリング基盤の設計・実装(アラート設計を含む)
- GitHub/GitLabを使ったコードレビューへの継続的な参加と改善提案
スキルチェックリストver.6を使った定期的な自己評価(3〜6ヶ月ごとを推奨)を並行して行うことで、成長が見えにくいスキル領域を可視化し、次に取り組むべき項目を明確にできます。
取得しておくべき資格はクラウド系・データ系の公的認定が市場評価に直結する
資格は実務経験を補う客観的な証明として機能します。転職時の書類選考や面接でも一定の効果があるため、優先度の高いものから計画的に取得しましょう。
優先度別:推奨資格一覧
| 優先度 | 資格名 | 発行機関 | 対応スキル領域 |
|---|---|---|---|
| ★★★ | AWS認定 データエンジニア – アソシエイト | Amazon Web Services | AWSデータサービス全般・ETL・DWH |
| ★★★ | Professional Data Engineer(GCP) | Google Cloud | BigQuery・Dataflow・Pub/Sub・ML連携 |
| ★★★ | データベーススペシャリスト試験 | IPA(情報処理推進機構) | DB設計・SQL最適化・セキュリティ |
| ★★ | DP-203:Azure Data Engineer Associate | Microsoft | Azure Synapse・Data Factory・分析基盤 |
| ★★ | 応用情報技術者試験 | IPA(情報処理推進機構) | IT全般の基礎力・設計思想の体系的証明 |
IPAのデータベーススペシャリスト試験はITSSレベル4相当の国家資格です。取得によってITSSレベルとの対応が明確になるため、日系企業の転職では特に評価されます。
クラウド資格と国家資格を組み合わせることで、技術の幅と深さを同時にアピールできます。
ミドル〜シニア層の次のキャリアはPM・データアーキテクト・MLOpsエンジニアが軸になる
ITSSレベル4以上になると、専門性をさらに深めるか、リーダーシップを担うポジションに進むかという選択肢が生まれます。それぞれのキャリアパスと必要なスキルを整理します。
シニアデータエンジニアが目指せるキャリアパスの分岐
| キャリアパス | 役割の概要 | 追加で必要なスキル |
|---|---|---|
| データアーキテクト | 企業全体のデータ基盤の設計方針を策定し、複数システム間のデータフローとガバナンスを設計します | エンタープライズアーキテクチャの理解・データメッシュ・データカタログ設計 |
| MLOpsエンジニア | 機械学習モデルの本番環境へのリリース・監視・再学習サイクルを管理します | MLflow・Kubeflow・Feature Storeの実装・CI/CDパイプラインとの連携 |
| プロジェクトマネージャー(PM) | データ基盤構築プロジェクトの計画・予算・リソース・進捗を統括します | プロジェクトマネジメントの資格(PMP等)・ステークホルダー管理 |
| データエンジニアリングマネージャー | データエンジニアチームのマネジメントと技術方針の策定を担います | ピープルマネジメント・採用・評価制度設計・技術ロードマップ策定 |
どのパスに進む場合も、データエンジニアとしての実装経験の深さと幅が土台になります。
特にデータアーキテクトとMLOpsエンジニアは技術的な連続性が高く、現在のデータエンジニア市場で特に需要の高い職種として注目されています。
11. まとめ|データエンジニアスキルセットは7領域の体系的な習得が転職成功への近道

データエンジニアに求められるスキルは、プログラミングやデータベース設計といった技術の基盤から、クラウド・ETL・データガバナンス、さらに生成AI対応やソフトスキルまで幅広くあります。
まずはPythonとSQLを軸に基礎を固め、クラウドとパイプライン構築へと段階的にステップアップすることが、転職・キャリアアップへの最短ルートです。
ITSSレベルとスキルチェックリストを活用した自己評価を定期的に行い、市場価値を継続的に高めていきましょう。