「LoRAという言葉をよく見かけるが、何ができる技術なのかわからない」
そう感じている方もいらっしゃるのではないでしょうか?今回は、「LoRA」について解説していきます。
なお「LoRA」には生成AI分野のLow-Rank Adaptation(低ランク適応)と、IoT通信のLong Range(長距離無線通信規格)の2種類があります。
本記事では生成AI・LLM文脈のLoRAのみを扱います。
- LoRAの仕組みと、なぜ今注目されているのかについて
- フルファインチューニング・RAG・QLoRAとの違いと選び方について
- 画像生成AIおよびLLMへの具体的な導入手順について

1. LoRAとは:AI効率化を実現する「低ランク適応」技術の基本
LoRA(読み方:ローラ)は、Low-Rank Adaptation(低ランク適応)の略称です。
2021年にMicrosoftの研究チームが発表したAIモデルのチューニング手法で、原著論文はarXiv(arXiv:2106.09685)で公開されています。
最大の特徴は、大規模モデルを丸ごと再学習しなくても、追加した小さな行列を学習するだけで特定のタスクに対応できる点です。
この仕組みが、AIを使う際のコストと技術的なハードルを大きく下げました。
AIのLoRAとIoT通信のLoRaは名前が同じ別の技術
「LoRA」という名前は、全く異なる2つの分野で使われています。混乱しないよう、以下の表で整理します。
| 名称 | 正式名称 | 分野 | 概要 |
|---|---|---|---|
| LoRA | Low-Rank Adaptation | 生成AI・機械学習 | 大規模モデルを効率よくチューニングする手法 |
| LoRa | Long Range | IoT・無線通信 | 低消費電力・長距離の無線通信規格(LPWA) |
本記事では以降、生成AI文脈のLoRAのみを紹介していきます。
LoRAが登場した背景:大規模モデルの「再学習コスト問題」
GPT-3などのLLMは、パラメータ数が数百億〜数千億規模あります。
こうした大きなモデルを特定タスク向けに再学習(フルファインチューニング)するには、大量のGPUメモリと長い計算時間が必要で、一般の企業や個人には現実的ではありませんでした。
LoRAはこの問題を解決するために登場しました。GPT-3にLoRAを適用した場合、従来比10,000倍ものパラメータ削減が実現されたことが報告されています。このコスト削減効果が、LoRAが急速に広まった理由です。
(出典:Ledge.ai )
LoRAの核心:元のモデルを変えずに「差分だけ学習する」発想
LoRAの仕組みを一言で表すと、「元のモデルには手をつけず、変化分だけ学習する」です。
通常のファインチューニングはモデル全体のパラメータを更新しますが、LoRAは元の重み行列を固定したまま、差分を2つの小さな行列AとBの積で表して、この追加行列だけを学習します。
2つの比喩でイメージしてみましょう。
- スポットライトのカラーフィルター:スポットライト(元モデル)自体は変えず、色付きフィルター(LoRAモジュール)を被せて演出を変えるイメージです。
- コンセントの変換アダプター:コンセント(元モデル)はそのままで、アダプター(LoRAモジュール)を差し込んで別の用途に使うイメージです。
つまり、元モデルの重みは固定され、追加したA・B行列だけが学習対象になります。学習するパラメータが少ないため、計算コストが大幅に下がります。
(参考:Cloudflare )
2. LoRAの仕組みを技術的に理解する:なぜ速く・安く動くのか
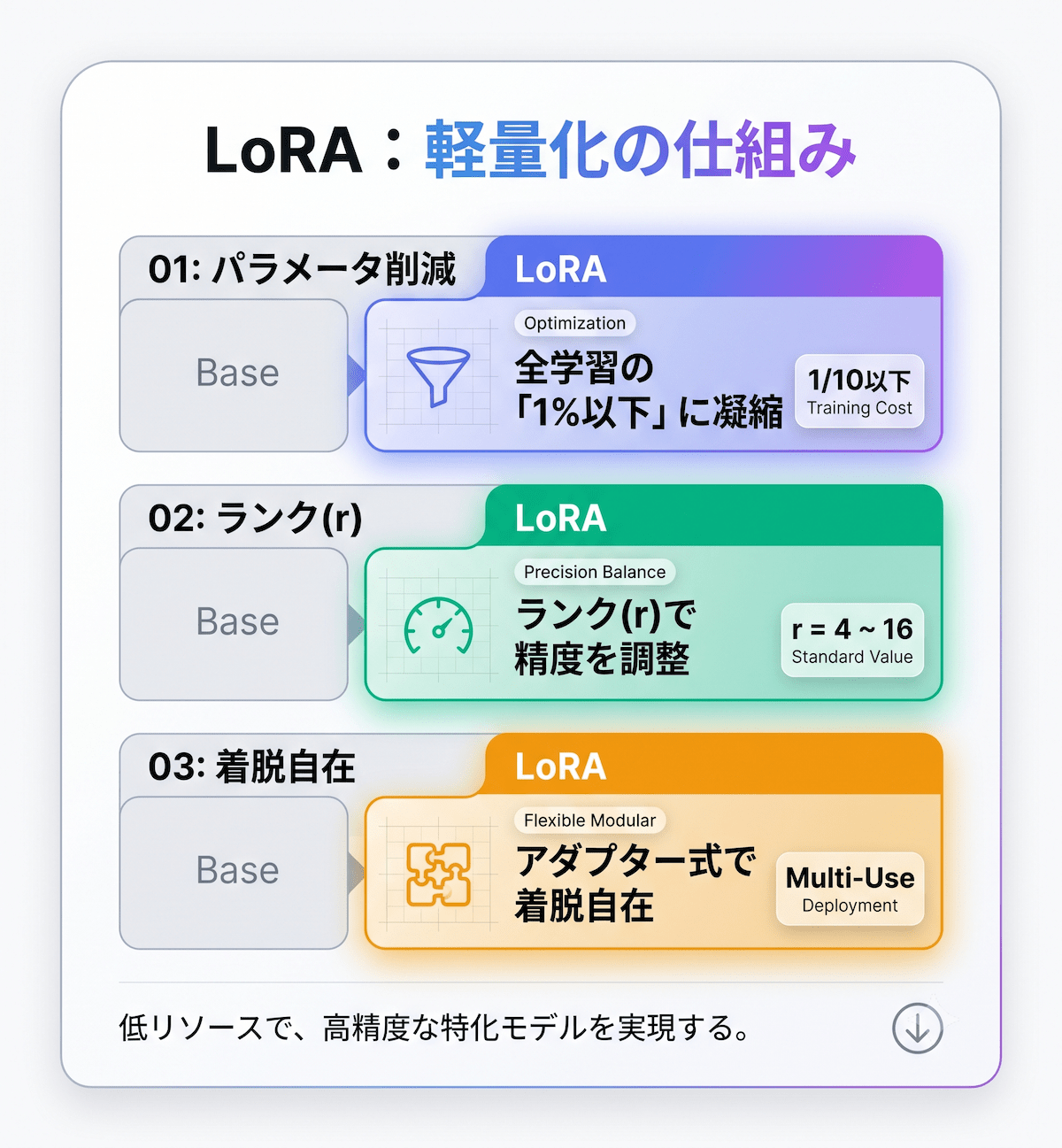
LoRAがリソースを節約できる理由は、学習するパラメータ数を徹底的に絞った設計にあります。
ここでは数値を交えながら、実際に自分の環境で使えるかどうかを判断するための情報を整理します。
学習対象パラメータが全体の1%以下に絞られる
フルファインチューニングはモデルの全パラメータを更新しますが、LoRAが更新するのは追加した行列のみです。その数はモデル全体の約0.01〜1%にとどまります。
この削減により、必要なGPUメモリはフルファインチューニング比で約1/3に減り、学習コスト全体では従来比1/10以下になり、パラメータ数を最大10,000倍削減できることが示されています。
動作環境の目安は以下の通りです。
- Stable Diffusion(画像生成AI)向け:VRAM 12GB以上のGPU(出典:AI総合研究所)
- LLM向け:VRAM 16GB以上のGPU(出典:hnavi)
ランク(r)の値が精度と軽さのバランスを左右する
LoRAには「ランク(r)」という設定値があります。追加する行列の大きさを決めるもので、値が小さいほど軽くてコストが低く、大きいほど精度が上がるトレードオフの関係です。
原著論文(arXiv:2106.09685)のTable 6では、ランクrを変えてもタスク精度がある程度保たれることが示されています。
実際の使用では、まずr=4〜16から試してみるのが一般的です。
(出典:arXiv:2106.09685 )
LoRAモジュールは「着脱可能」なため1つのモデルを多用途に使える
LoRAの重みファイルはベースモデルとは別に保存・管理できます。使い方のオプションは2つあります。
①ベースモデルへ統合(マージ)
LoRAの重みをモデルに取り込んで一体化させる。推論が速くなるメリットがあります。
②アダプターとして着脱
LoRAファイルを独立したまま保持し、用途に合わせて差し替える。複数の用途で使い回す場合に向いています。
「コンセントのアダプター」のたとえ通り、1つのベースモデルに対して用途別のLoRAを複数用意し、切り替えながら使えるため、運用コストをおさえられます。
(参考:Cloudflare )
3. LoRAと他手法の違いを比較する:RAG・QLoRA・フルFTの選び方

AIのカスタマイズ手法はいくつかあり、目的・コスト・環境によって向き不向きが異なります。まず4手法を一覧で比較し、その後それぞれの特徴を説明します。
| 手法 | 学習対象 | コスト | 向いているケース |
|---|---|---|---|
| フルファインチューニング | 全パラメータ | 高 | 大量データ・最高精度が必要な場合 |
| LoRA | 追加行列のみ | 低 | 少ないデータ・低コスト・特定分野への特化 |
| QLoRA | 追加行列のみ(量子化) | 最低 | GPUリソースが特に少ない場合 |
| RAG | モデル変更なし | 低〜中 | 最新情報の参照・検索と連動させたい場合 |
RAGとLoRAは目的が根本的に異なる別の手法
RAG(Retrieval-Augmented Generation:検索拡張生成)は、社内文書やデータベースなどの外部情報をその都度検索して参照しながら回答を生成する手法です。モデル自体は変えません。
一方LoRAは、モデルの振る舞い・文体・専門知識そのものを変えます。
最新情報の参照や社内文書への回答改善にはRAGが向いており、特定分野の言い回しや判断基準をモデルに覚えさせたい場合はLoRAが向いています。
「常に最新の製品仕様でQ&Aに答えさせたい」ならRAG、「医療分野の専門的な文体で回答させたい」ならLoRAを選ぶのが自然です。
QLoRAはLoRAをさらに低コスト化した派生技術
QLoRA(Quantized LoRA:量子化LoRA)は、LoRAに4ビット量子化を組み合わせてGPUメモリの消費をさらに減らした手法です。量子化とは、数値の精度を下げてデータ量を圧縮する処理です。
使い分けの目安は、品質と速度のバランスを取りたいならLoRA、GPUリソースが特に少ない環境ならQLoRAです。
ただし量子化によってわずかに精度が落ちるケースもあるため、コストと品質のバランスを確認した上で選んでください。
(出典:LISKUL )
手法選択は「データ量・予算・タスクの性質」の3軸で判断する
どの手法を使うかは、次の3点で判断するとスムーズです。
データ量:
学習データが豊富で最高精度を求めるならフルFT、少量データで特定分野に絞るならLoRA
予算・GPU環境:
GPU環境がある程度整っていればLoRA、リソースが非常に少ないならQLoRA
タスクの性質:
最新情報の参照が必要ならRAG、文体や判断基準を覚えさせたいならLoRA
医療・法務・金融などの専門分野では、業界固有の言葉づかいやルールをモデルに学ばせるLoRAが特に役立ちます。
迷ったときはまずLoRAで試し、精度が足りなければフルFTへ、GPUが足りなければQLoRAへ切り替える流れが現実的です。
4. LoRAの使い方:LLMと画像生成AIでの主な活用シーン

LoRAは「LLMの業務特化」「画像生成AIのスタイル固定」「企業での業務活用」という3つの場面で広く使われています。それぞれ具体的に見ていきます。
LLMを特定業務・専門分野に特化させる
汎用LLMにLoRAを適用すると、特定業界の用語・文体・判断基準を覚えさせることができます。代表的な使い方は以下の通りです。
- 社内ドキュメントのQ&A自動化:規程集・マニュアル・議事録を学習させ、社内問い合わせ対応を効率化する
- カスタマーサポートの回答品質向上:製品固有の言葉と回答スタイルを覚えさせ、一貫した顧客対応を実現する
- 法務文書の要約・チェック補助:契約書レビューの流れを補助し、担当者の確認時間を減らす
パーソル総合研究所「生成AIとはたらき方に関する実態調査」によると、生成AIの活用でタスクにかかる時間が平均16.7%削減されたことが示されています。
業務に特化させたLoRAを使えば、この効果をさらに高められる可能性があります。
(出典:パーソル総合研究所 )
Stable Diffusionで特定の画風・キャラクターを安定して再現する
画像生成AIの分野では、LoRAは特定の画風・キャラクター・ポーズを安定して再現するために使われています。主な用途は以下の通りです。
- 画風の固定:特定のイラストスタイルや写真のトーンを一貫して生成する
- キャラクターの再現:外見的な特徴を保ちながら様々な構図で生成する
- ポーズや構図の指定:決まったポーズや構図を安定して出力する
基本の使い方は、checkpointモデル(ベースモデル)にLoRAファイルを組み合わせるだけです。Civitai(civitai.com)にはコミュニティ製のLoRAが多数公開されており、自作しなくても試すことができます。
製造・金融・医療など企業での活用可能性
企業での活用も広がっています。製造業では品質検査の自動化、金融では審査補助、医療では診断サポートツールの開発といったケースが検討されています。
IBMも企業向けAIの文脈でLoRAを採用・紹介しており、信頼性の高い手法として位置づけています。専門のAI開発チームがなくても、自社の業務データを使って特化型AIを作れる点が、LoRAの大きな魅力です。
(出典:IBM Think )
【コラム】実際にLoRAを使うとどう変わるか:使用例イメージ
LLM活用例:法律事務所による契約書レビューAIの作成
ある法律事務所では、汎用LLMをベースに自社の契約書レビューデータ数千件でLoRAを学習させました。
HuggingFaceのPEFTライブラリとLLaMAベースのモデルを組み合わせ、VRAM 16GBのGPUで約8時間で完了。
導入後、弁護士が初期レビューにかける時間が従来比で約40%減ったと報告されています。
画像生成例:自分の画風を再現するLoRAでSNSコンテンツを効率化
あるクリエイターは、自分のイラスト作品20枚をKohya_ss GUIで学習させ、画風を再現するLoRAを作成しました。
Stable Diffusion WebUIにLoRAを適用することで、新しいテーマのイラストをプロンプト一つで生成できるようになり、SNS投稿1点あたりの制作時間を数時間から数十分に短縮しています。
■日本でエンジニアとしてキャリアアップしたい方へ
海外エンジニア転職支援サービス『 Bloomtech Career 』にご相談ください。「英語OK」「ビザサポートあり」「高年収企業」など、外国人エンジニア向けの求人を多数掲載。専任のキャリアアドバイザーが、あなたのスキル・希望に合った最適な日本企業をご紹介します。
▼簡単・無料!30秒で登録完了!まずはお気軽にご連絡ください!
Bloomtech Careerに無料相談してみる
5. LLM向けLoRAの導入手順:PEFTライブラリを使った実装の流れ

LLMにLoRAを適用したいエンジニア・研究者・ビジネス担当者向けに、HuggingFaceのPEFTライブラリを使った学習フローを説明します。
コードの詳細は省略し、ツール名・設定項目・推奨値を中心に紹介します。
LLM向けLoRA学習に必要な環境と最低スペックの目安
学習を始める前に、以下の環境を用意します。
推奨ハードウェア
主要ライブラリ
- Python:3.9以上を推奨
- PyTorch:深層学習フレームワーク
- Transformers(HuggingFace):ベースモデルの読み込みと推論に使用
- PEFT(HuggingFace):LoRAなどの効率的なチューニングを管理するライブラリ
MicrosoftのLoRA公式実装はGitHub(github.com/microsoft/LoRA)で公開されており、参考として活用できます。
PEFTライブラリを使ったLoRA学習は4つのステップで実行できる
基本的な学習の流れは4ステップです。どのステップでも元モデルの重みは変わらないという点を意識しながら読み進めてください。
ステップ1:ベースモデルの選定・読み込み
HuggingFace Hubから目的に合ったベースモデル(LLaMA、Mistral、Qwen など)を選びます。この時点でモデルの重みは固定された状態になります。
ステップ2:LoRAConfigの設定
PEFTライブラリのLoRAConfigで、以下の主要パラメータを設定します。
- ランク(r):精度と軽さのバランスを決める値。まずr=4〜16から試すのが一般的
- 対象レイヤー(target_modules):LoRAを適用するAttentionレイヤーなどを指定。モデルによって異なります
- lora_alpha:学習のスケーリング係数。rと同じ値から始めると安定しやすい
ステップ3:学習データの準備・トークン化
タスク向けの学習データを用意し、モデルが読める形式(トークン列)に変換します。
データの質がLoRAの出力品質を直接左右するため、なるべくノイズの少ない整理済みデータを使いましょう。
ステップ4:学習実行・チェックポイントの保存
学習を実行すると、更新されるのはLoRAモジュール(A・B行列)のみで、元のモデルファイルは変わりません。学習後はLoRAモジュールだけを軽量ファイルとして保存します。
学習後のLoRAモジュールはモデルへの統合と差し替えの両方が可能
学習済みLoRAモジュールの使い方は2つあります。
- ①ベースモデルへの統合(マージ):LoRAをモデルに取り込んで一体化させる。推論速度が上がります
- ②アダプターとして差し替え:LoRAを独立ファイルのまま保持し、用途に応じて切り替える。複数の用途で使い回したい場合に便利です
また、「いつ・どのLoRAを・どのモデルに使ったか」を記録しておくと、問題が起きたときに原因を特定しやすくなります。運用開始前にバージョン管理の仕組みを整えておくと安心です。
6. 画像生成AI向けLoRAの導入手順:Kohya_ss GUIでノーコードで作る方法
Stable DiffusionでLoRAを自作したい方向けに、Kohya_ss GUIを使ったノーコードの学習フローを説明します。
(出典:AI総合研究所 )
Stable Diffusion向けLoRA学習に必要な環境と画像枚数の目安
推奨ハードウェア
- GPU:VRAM 12GB以上が目安
- GPUが足りない場合はGoogle Colabでも実行できます
学習用画像の準備
- 推奨枚数:20〜30枚
- 顔・全身・バストアップなど多様なアングルや構図を入れる
- ノイズや余分な要素が少ない、きれいな画像を選ぶ
Kohya_ss GUIを使ったLoRA学習は4つのステップで完結する
ステップ1:学習用画像の収集・切り抜き
学習させたいキャラクターや画風の画像を集め、顔・全身・バストアップなど様々な構図を揃えます。
画像サイズは512×512または768×768ピクセルに合わせるのが基本です。
ステップ2:キャプション付け
各画像の特徴を説明するテキストファイル(.txtファイル)を作ります。
例えば「a woman with short black hair, smiling, white background」のように、画像の内容を具体的に書きます。キャプションの精度が学習品質を大きく左右するため、この工程は丁寧に行いましょう。
ステップ3:Kohya_ss GUIでの設定
Kohya_ss GUIを起動して、以下のパラメータを設定します。
- バッチサイズ:1〜2(VRAMの容量に応じて調整)
- ステップ数(Max train steps):1,500〜3,000を目安に(画像枚数や品質に応じて調整)
- 学習率(Learning rate):1e-4前後から始めて、結果を見ながら調整する
ステップ4:学習実行・ファイルの出力
学習が完了すると、.safetensors形式のLoRAファイルが出力されます。
このファイルをStable Diffusion WebUIのLoRAフォルダに置くだけで、すぐに使い始められます。
作成したLoRAはCivitaiで配布されているモデルとも組み合わせて使える
自作LoRAは、Stable DiffusionのcheckpointモデルやCivitai(civitai.com)で公開されているLoRAと自由に組み合わせられます。
例えばキャラクターのLoRAとリアル写真風のcheckpointモデルを合わせれば、より高品質な出力が得られます。
さらに応用として、複数のLoRAを重み付けして同時に適用する方法もあります。「キャラクターLoRA(重み0.8)+画風LoRA(重み0.5)」のように設定することで、複数の特性を組み合わせた画像が生成できます。
各LoRAの推奨設定やサンプル画像はCivitai(civitai.com)のモデルページで確認できます。
7. LoRAの著作権リスクと法的な注意点

LoRAを業務や商用コンテンツ制作に使う際は、著作権のリスクを理解しておくことが大切です。
日本の著作権法上は、第30条の4により情報解析目的の利用が原則として認められています。ただし、享受目的が含まれる場合はこの限りではありません。
個別のケースについては弁護士・弁理士などの専門家にご相談ください。
AI学習は著作権法第30条の4により原則として適法とされている
日本の著作権法第30条の4は、情報解析(機械学習など)を目的としたAI学習について、著作権者の許可なく著作物を利用できると定めており、原則として適法とされています。
ただし例外があります。「享受目的」——著作物そのものを楽しむ・消費することが目的の利用——が含まれると、適法かどうか問われる可能性があります。
例えば、特定の著作権者の作品を大量に学習させて「その作品そのものを模倣・代替する」ことが目的のLoRA作成は、この例外に当たるリスクがあります。
生成物の商用利用には3つの観点でリスク確認が必要
LoRAで作ったコンテンツを商用利用する際は、以下の3点を事前に確認しましょう。
①学習データのライセンス確認
学習に使った画像やテキストに著作権がある場合、無断使用が問題になることがあります。
著作権フリーの素材やクリエイティブ・コモンズのものを使うか、自分が権利を持つデータを使うのが基本です。
②生成物と元の著作物の類似性チェック
生成物が学習元の著作物と見た目や文体が似すぎていると、著作権侵害とみなされるリスクがあります。
特定のイラストレーターや作家のスタイルを模倣したLoRAを商用利用する際は、慎重に判断してください。
③配布モデルの利用規約確認
CivitaiやHuggingFaceのモデルには利用規約(モデルカード)が設定されています。
商用利用の可否が明記されている場合があるため、必ず事前に確認しましょう。
社内ガイドライン整備が企業によるLoRA活用の第一歩
企業でLoRAを業務利用する際は、以下の3点を盛り込んだ社内ガイドラインを用意しておくと安心です。
①学習データの収集・使用ルールの明文化
使えるデータの種類・出所・ライセンスの確認フローを決めます。社内データと外部データの区別、確認の担当者も明確にしておきましょう。
②生成物の社内レビュープロセスの設定
LoRAで作ったコンテンツを外部公開や業務利用に使う前に、著作権・品質・倫理の観点から社内でチェックする流れを作ります。
③外部公開・商用利用時の法務確認フロー
生成物を外部に公開・販売・配布する際は、法務部門か外部の専門家に確認するフローを設けます。
医療・金融・法務など規制が厳しい業界では、より丁寧な対応が求められます。
ルールを整えた上で使い始めることが、リスクを抑えながらLoRAを長く使い続けるための近道です。
ITエンジニアの転職に興味がある方は
ITエンジニア専門の転職エージェント「BLOOMTECH CAREER」にご相談ください。年収100万円UPの実績・LLM/生成AI求人多数・非公開案件100社以上。
転職を考え始めたら、まず無料相談であなたの正しい市場価値をご提示します。
8. LoRAのビジネス導入で押さえておくべき費用対効果と運用設計

DX推進担当者・経営層向けに、LoRA導入の費用対効果と、長期的に使い続けるための運用設計のポイントをまとめます。
導入によるコスト削減と生産性向上は数値で裏付けられている
学習コスト面
フルファインチューニング比で1/10以下に削減できることが示されています。自社のGPUで実行できるケースが増えるため、クラウドGPUへの依存を下げられます。
生産性の面
パーソル総合研究所「生成AIとはたらき方に関する実態調査」によると、生成AIの活用でタスクにかかる時間が平均16.7%削減されたことが示されています。
業務に特化したLoRAを活用すれば、この削減率をさらに高められる可能性があります。
(出典:パーソル総合研究所 )
ADKマーケティング・ソリューションズの調査では、3人に1人が生成AIを月複数回以上活用していることが示されており、企業でのAI活用が当たり前になりつつあります。
(出典:ADKマーケティング・ソリューションズ )
モデルドリフトと品質低下を防ぐ運用設計が長期活用の鍵
LoRAを導入した後に注意したいのが、モデルドリフト(時間とともに精度が下がる現象)です。
業務環境の変化やデータの変動・用語の更新などにより、最初は高精度だったLoRAの出力が徐々に落ちていくことがあります。
品質を長期的に保つために、以下の3点を運用前から設計しておくことをおすすめします。
(出典:LISKUL )
①定期的な精度チェック
月次や四半期ごとに、固定の評価データを使ってLoRAの出力品質を測定します。精度の低下に早めに気づけるよう、判断基準をあらかじめ決めておきましょう。
②学習データの更新サイクルの設計
業務環境の変化に合わせて学習データを更新し、LoRAを再学習するタイミングを決めておきます。
データが古くなるとLoRAの効果も落ちるため、更新の頻度と判断基準を決めておくことが大切です。
③バージョン管理
「どのLoRAを・いつ・どのモデルに使ったか」を記録・管理します。問題が起きたときに原因を特定しやすくなり、前のバージョンへの切り戻しもスムーズになります。
医療・金融・法務などの規制が厳しい業界では、出力品質の管理がより厳しく問われるため、特に丁寧な運用体制が必要です。
9. まとめ:LoRAとは、AI民主化を加速する低コスト・高効率のチューニング技術

LoRAは大規模AIモデルを低コスト・高効率でカスタマイズできる技術であり、画像生成AIからLLM・ビジネス活用まで幅広い場面で使われています。
フルFT比で学習コストを1/10以下に抑えながら高い精度を維持できる点が強みです。
著作権や運用ルールをしっかり整えた上で活用することで、大企業や研究機関に限らず誰でも大規模AIを自社の業務に合わせて使えるようになっています。
ITエンジニアの転職に興味がある方は
ITエンジニア専門の転職エージェント「BLOOMTECH CAREER」にご相談ください。年収100万円UPの実績・LLM/生成AI求人多数・非公開案件100社以上。
転職を考え始めたら、まず無料相談であなたの正しい市場価値をご提示します。