
コードレビューは、バグ発見にとどまらず、チームの知識共有・品質基準の統一・技術的負債の予防まで担う、ソフトウェア開発の根幹プロセスです。
初めてレビューを担当するエンジニアから組織への導入を検討するリーダー、日本の開発現場で即戦力として働きたい外国人エンジニアまで、定義・目的・手順・観点・AI時代の最新動向を整理します。
- コードレビューの定義・目的と、開発現場での具体的な実施手順について
- 現場ですぐ使えるチェックリストと、チームの関係を壊さない指摘の方法について
- AI導入後にレビューのボトルネックが増す理由と、人間が担うべき本質的な役割について

1. コードレビューとは?ソースコードの品質を守る第三者検証プロセス

コードレビューの定義と、テスト・デバッグとの違い、実施形式の種類を整理します。
コードレビューとは、記述者以外がコードを確認し品質を高める工程のことである
コードレビューとは、「ソフトウェア開発工程で見過ごされた誤りを検出・修正することを目的として、ソースコードの体系的な検査(査読)を行う作業」のことです。
コードを提出する側をレビューイ、確認・評価する側をレビュアーと呼びます。
コードレビューは「テスト」や「デバッグ」とは別の工程です。テストは自動化されたシナリオで動作の正否を確認し、デバッグは既知のバグの原因を特定・修正します。
コードレビューは人間の判断と経験を直接コードに反映させる点が特徴で、「設計の意図」「命名の適切さ」「将来の保守性」といった観点はツールでは評価できません。
| 立場 | 呼称 | 主な責務 |
|---|---|---|
| コードを提出する側 | レビューイ(Author) | 変更内容・目的・テスト結果を明示し、レビュアーに確認を依頼する |
| コードを確認する側 | レビュアー(Reviewer) | 観点に基づいてコードをチェックし、根拠と代替案を添えてフィードバックする |
コードレビューには同期型と非同期型の2種類がある
コードレビューの形式は同期型と非同期型の2種類に分かれます。
どちらが優れているということはなく、チームの規模・開発スタイル・リモートワークの有無で使い分けます。
| 項目 | 同期型(ペアプログラミング・対面レビュー) | 非同期型(プルリクエスト・マージリクエスト) |
|---|---|---|
| フィードバック速度 | 即時。質問・回答をリアルタイムでやり取りできる | 非即時。コメント後に確認・修正のサイクルが生じる |
| 工数・コスト | 大きい。レビュアーとレビューイが同じ時間を確保する必要がある | 小さい。各自のスケジュールで対応できる |
| 主な手法 | ペアプログラミング、ウォークスルー、インスペクション | GitHub / GitLabのプルリクエスト・マージリクエスト |
| 向いている場面 | 小規模チーム・新人育成・難易度の高い設計変更 | 中〜大規模チーム・リモートチーム・分散開発 |
| 現代での主流度 | 補完的に活用 | ★ 現代の主流 |
同期型はコミュニケーションの密度が高く、ジュニアエンジニアの育成や複雑な設計変更の確認に向いています。
非同期型はプルリクエストのUI上で差分を確認しながらコメントを残す形式で、時間の制約が少ないため現代のグローバルチームでは主流です。
2. コードレビューの目的|バグ発見だけではない4つの本質的な価値
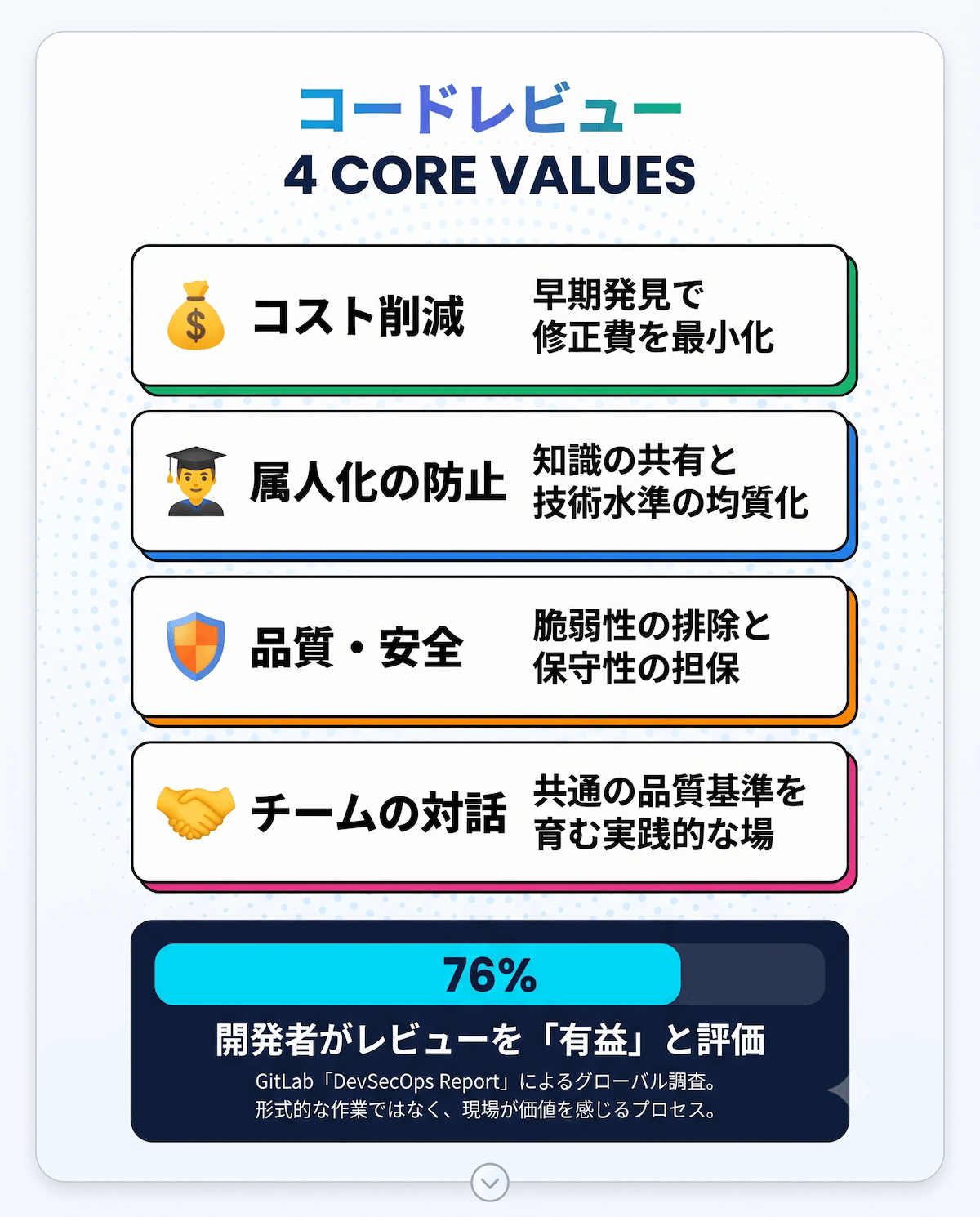
コードレビューはなぜ必要なのか。バグ発見以外の4つの価値を、データをもとに解説します。
コードレビューの第一目的はバグ・仕様漏れの早期発見によるコスト削減である
コードレビューが開発フローに組み込まれる最大の理由は、バグ・仕様漏れを早期に見つけることでコストを大幅に削減できるからです。
IPA(情報処理推進機構)の「ソフトウェア開発データ白書」によると、開発フェーズで修正されるバグの対応コストは、テストフェーズやリリース後に発見された場合の数倍〜数十倍低いとされています。
コードを書いた本人は、自分の思い込みや見落としに気づきにくいものです。第三者の目を入れることで、ロジックの誤り・境界値の抜け・仕様書との食い違いを、リリース前に取り除けます。
レビューは属人化を防ぎチーム全体の技術水準を底上げする
コードレビューの第二の価値は、チームの知識共有と技術水準の均質化です。
コードを「個人の成果物」ではなく「チームの共有財産」として扱うことで、特定のメンバーしか読めないコードが増える「属人化」を防げます。
担当者が不在・退職した際にシステムがブラックボックスになるリスクは、特に日本の開発現場で深刻です。
複数のメンバーがコードを継続的に読む習慣を持つことで、知識が自然にチーム全体に広がります。多国籍チームでも、コードレビューは共通の品質基準を持つための実践的な場になります。
セキュリティと保守性の担保もコードレビューの重要な役割である
コードレビューは、セキュリティ上の問題を早期に取り除く役割も担います。
内閣サイバーセキュリティセンター(NISC)の「サイバーセキュリティ 2025」でも、ソフトウェアのセキュリティ確保には開発プロセス自体への組み込み(セキュリティ・バイ・デザイン)が不可欠とされており、コードレビューはその具体的な実践手段の一つです。
保守性の面でも効果があります。「将来の変更に耐えられる設計か」を継続的に確認することで、技術的負債の蓄積を抑えられます。
問題を後回しにするほど改修コストは膨らむため、早い段階で手を打つことが重要です。
GitLabの調査では開発者の76%がコードレビューを「有益」と評価している
GitLabの年次レポート「DevSecOps Report」によると、世界の開発者の76%がコードレビューを「有益」と評価しています。
この数値は、コードレビューが単なる慣習ではなく、現場エンジニアが実際に価値を感じているプロセスであることを示します。
調査はグローバルな開発者を対象としているため、国籍・文化を問わず共通の参考データとして使えます。
「形式的な作業」としてではなく、「チームで品質を守るための対話」として捉え直すきっかけになるデータです。
出典:GitLab「DevSecOps Report」(英語版)
3. 日本の開発現場におけるコードレビューの実態——IPAデータが示す現状と課題

日本の開発現場はコードレビューの浸透度や文化面でグローバルと異なる特徴があります。IPAの公的データをもとに実態を確認します。
IPA調査が示す日本のソフトウェア開発現場でのコードレビュー普及状況
IPA(情報処理推進機構)の「2024年度ソフトウェア動向調査」は、国内の開発現場における手法の実態を詳細に調べたものです。
「ソフトウェアに対する考え方や開発の実態、産業分野ごとのレガシーシステムの現状と課題を把握すること」を目的として実施されており、日本の開発水準を客観的に知るための公的な資料として活用できます。
調査が明らかにした課題の一つが、レガシーシステムの温存がコードレビュー文化の浸透を妨げているという実態です。
長年改修を積み重ねたシステムではコードの読みやすさが低く、担当者以外が理解するコストが高くなります。その結果、レビューが形式的なチェックにとどまり、実質的な品質管理の機能を果たせていないケースが見られます。
日本で就労を希望する外国人エンジニアにとっても、このギャップを事前に把握しておくことは重要です。
日本の開発現場ではコードレビューの形式・文化に独自の特徴がある
日本のコードレビュー文化には、グローバルスタンダードとは異なる特徴があります。主なポイントを以下に整理します。
日本語コメント文化
レビューコメントは日本語が大半で、「〜ではないでしょうか」「〜の方がよいかもしれません」といった婉曲表現が多く使われます。外国人エンジニアには意図が伝わりにくいことがあるため注意が必要です。
プルリクエスト文化の浸透度格差
スタートアップや外資系企業ではGitHub / GitLab を使ったプルリクエストレビューが普及しています。一方、大手SIerや金融・製造業の社内開発部門では、対面やメールでのレビューが残っているケースもあります。
企業種別ごとのレビュー文化の違い
- SIer:ウォーターフォール型の工程管理のなかでレビューを位置づけ、書面での承認を重視する傾向がある
- スタートアップ:非同期型のプルリクエストレビューが主流で、スピードと継続的デプロイを重視する
- 外資系企業:グローバルのコーディング規約・英語コメントが標準で、日本オフィスでも準拠が求められることが多い
日本のソフトウェア開発のモダナイゼーションとコードレビューの関係
IPAの調査はレガシーシステムの「ブラックボックス化」リスクを繰り返し指摘しています。
ブラックボックス化とは、システムの内部ロジックを理解しているエンジニアが限られ、改修・移行・障害対応が難しくなる状態です。
コードレビューが定着していれば、複数のメンバーがコードの文脈を共有し続けられるため、このリスクを防ぎやすくなります。
日本企業のDX推進において
コードレビュー文化の整備は急務です。レガシーシステムの近代化(モダナイゼーション)を進める際には、既存コードの理解と新しい設計への移行判断が同時に求められます。
コードレビューを通じてチームの共通認識を高めることが、その推進の鍵となります。
出典:IPA「2024年度ソフトウェア動向調査 簡易分析レポート」
4. コードレビューの手順|準備から完了まで5つのステップ
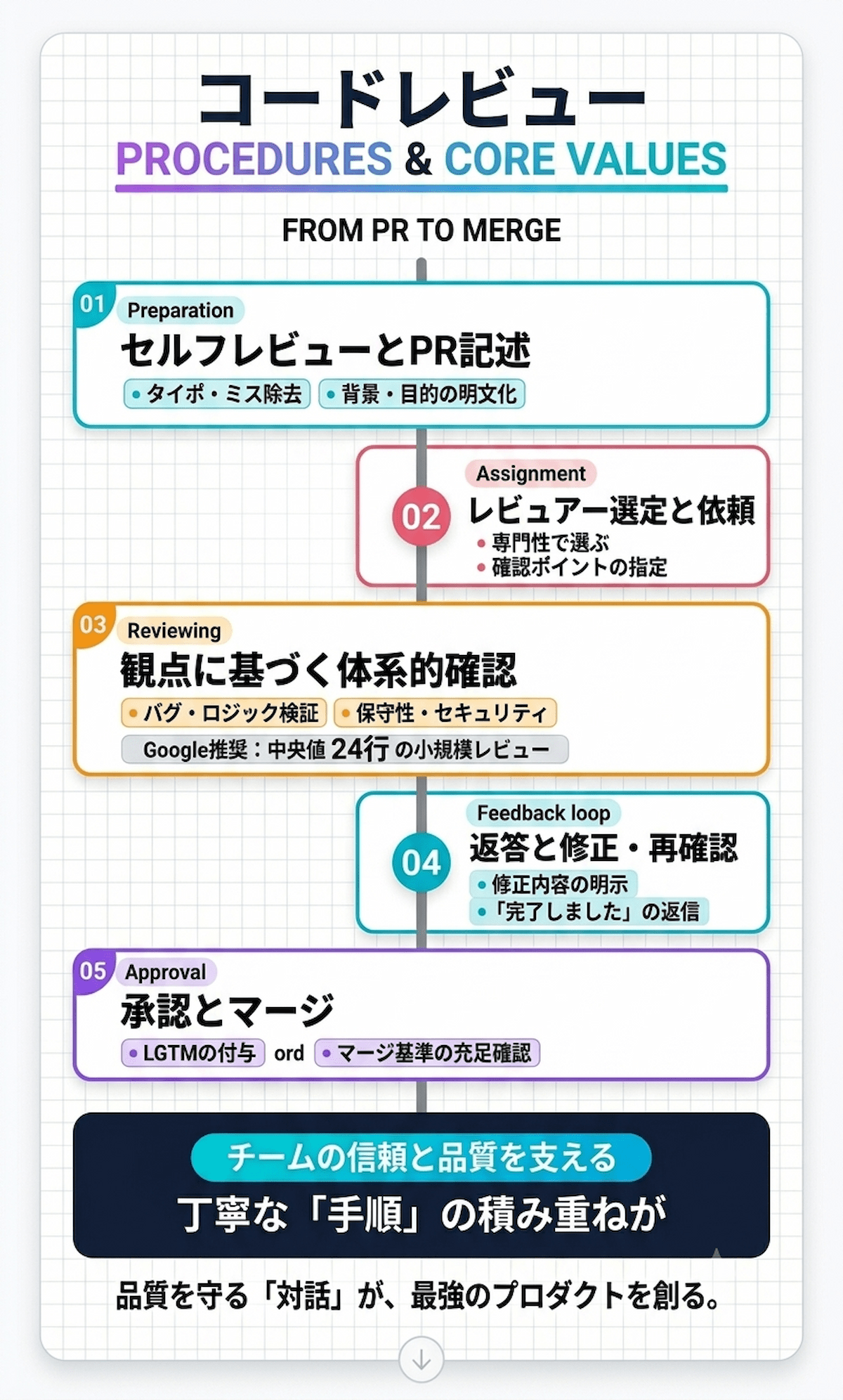
コードレビューは「コードを読んでコメントする」だけの作業ではありません。
依頼の準備から承認・マージまでの流れを理解することで、チーム全体の効率と品質が上がります。実務で機能する5ステップを以下に解説します。
- レビュー依頼前の準備(セルフレビュー・PR記述)
- レビュー依頼(レビュアー選定・依頼文作成)
- レビューの実施(観点に基づく確認)
- フィードバックへの返答と修正(コメント対応・再レビュー)
- 承認とマージ(完了基準の確認)
ステップ1:レビュー依頼前の準備|自己レビューとプルリクエストの明確化
依頼する前に、まずレビューイ自身がコードを読み直す「セルフレビュー」を行います。
時間を置いて自分のコードを客観的に読み返すことで、タイポ・ロジックの穴・不要なデバッグコードといった初歩的なミスを事前に取り除けます。
レビュアーの時間を初歩的なミスに使わせないことも、チームへの配慮です。
次に、プルリクエスト(PR)の説明文を丁寧に書きます。記載すべき内容の目安は以下のとおりです。
- 変更の目的・背景(なぜこの変更が必要か)
- 変更内容の概要(何を、どのように変えたか)
- テスト済みの確認事項・動作確認結果
- 特に確認してほしいポイント(任意)
日本の現場では「変更内容は差分を見ればわかる」という暗黙の前提から、PR説明文が簡素になりがちです。ただ、丁寧な説明文はレビュアーの理解を助け、レビューの質を上げます。
ステップ2:レビュー依頼|適切なレビュアーの選定と依頼文の書き方
誰に依頼するかはレビューの質を左右します。レビュアーを選ぶ際は以下の3点を考慮します。
- 専門領域との一致:変更内容に関係する技術領域の知識を持つ人を選ぶ
- 対象コードへの理解度:対象モジュールや機能の背景を知っているメンバーを優先する
- 経験値のバランス:シニアメンバーだけに集中させず、ジュニアメンバーも巻き込んで知識共有を促す
依頼文には「何を確認してほしいか」を明示します。
「全体的に見てください」という曖昧な依頼よりも、「認証ロジックのセキュリティ観点を特に確認してください」と絞り込む方が、レビュアーは集中でき、精度の高いフィードバックが返ってきます。
ステップ3:レビューの実施|観点に基づく体系的な確認
レビュアーは、後述するH2-5の6カテゴリの観点に基づいてコードを確認します。ここで重要なのは、一度のレビューで確認する変更規模を絞ることです。
Googleの論文「Modern Code Review: A Case Study at Google」によると、Googleのプルリクエストの変更行数の中央値は24行です。
小さな変更を高頻度でレビューする習慣こそが、品質と効率を両立させるポイントです。一度に数百〜数千行の変更が来ると、レビュアーの集中力が分散し、重大なバグを見落とすリスクが上がります。
出典:CTC教育サービス「第42回 Googleのソフトウェア開発におけるコードレビューの役割」
ステップ4:フィードバックへの返答と修正|コメントへの対応と再レビュー
レビューイはコメントに対し、「修正した」または「修正しなかった(理由つき)」を明示して返答することがチームの信頼を生む基本作法です。
コメントを理由なく無視した状態はレビュアーのモチベーションを損ない、やがてレビューの形骸化につながります。
修正が完了したら、再度レビュアーに確認を依頼します。修正箇所のコメントに「対応しました」と返信するか、差分を明示することで、レビュアーがスムーズに再確認できます。
ステップ5:承認とマージ|完了基準の定義
レビュアーが問題なしと判断したことを示すフレーズとして、LGTM(Looks Good To Me)が広く使われています。
GitHub / GitLabでは「Approve(承認)」のボタン操作として実装されており、承認を得てはじめてマージが許可されるのが一般的な運用です。
重要なのは、承認基準をチームで事前に合意しておくことです。「何名の承認でマージ可能か」「どのカテゴリの指摘は必ず修正してからマージするか」といったルールが曖昧なままでは、「とりあえずLGTM」が横行します。
■日本でエンジニアとしてキャリアアップしたい方へ
海外エンジニア転職支援サービス『 Bloomtech Career 』にご相談ください。「英語OK」「ビザサポートあり」「高年収企業」など、外国人エンジニア向けの求人を多数掲載。専任のキャリアアドバイザーが、あなたのスキル・希望に合った最適な日本企業をご紹介します。
▼簡単・無料!30秒で登録完了!まずはお気軽にご連絡ください!
Bloomtech Careerに無料相談してみる
5. コードレビューの観点|現場で即使える6カテゴリのチェックリスト

「何を見るか」が明確でないと、レビュアーによって指摘の粒度がバラバラになり、品質の標準化ができません。
以下に現場で即使える6カテゴリのチェックリストを示します。
可読性:他者が理解しやすいコードかどうかが最初の確認点である
コードは「書かれる回数より読まれる回数の方が多い」ものです。他者が直感的に理解できる書き方になっているかを最初に確認します。
| 確認項目 | チェックのポイント |
|---|---|
| 命名規則 | 変数・関数・クラス名が意図を的確に表しているか。略語の多用、曖昧な名前(data, tmp, flag 等)がないか |
| コメントの適切さ | 「何をしているか」ではなく「なぜそうしているか」が書かれているか。自明な処理へのコメントが多すぎないか |
| コードの長さ・ネスト | 1関数が単一の責務に収まっているか。ネストが深すぎて読みにくくなっていないか |
多言語が混在するチームでは、英語の命名規則を統一することが特に大切です。
日本語変数名やローマ字命名(例:nenrei、shinseiDate)は、外国人エンジニアとの協業で可読性を大きく下げます。
正確性:仕様を満たし、バグのないロジックになっているかを検証する
コードが仕様どおりに動作し、予期しない入力や状態にも適切に対応できるかを確認します。
| 確認項目 | チェックのポイント |
|---|---|
| 境界値・異常系処理 | 最大値・最小値・ゼロ・空文字・null などに対して適切に処理されているか |
| 例外処理の網羅 | 例外が発生しうる箇所でキャッチ・ハンドリングされているか。例外を黙って握りつぶしていないか |
| 条件分岐の抜け漏れ | 考慮されていない分岐パターンがないか。仕様書・要件定義との照合が必要な箇所を特定できているか |
セキュリティ:脆弱性を生む実装パターンを早期に排除する
セキュリティ観点のレビューは、WebアプリケーションやAPIを含む変更では必須です。
開発段階で脆弱性を取り除くコストはリリース後の対応より格段に低いため、見落としがないよう体系的に確認します。
| 確認項目 | チェックのポイント |
|---|---|
| 入力値バリデーション | 外部からの入力(フォーム・APIパラメータ等)が適切に検証・サニタイズされているか |
| 認証・認可 | アクセス制御が正しく実装されているか。権限のないユーザーがリソースにアクセスできないか |
| シークレット情報の管理 | APIキー・パスワード・トークン等がソースコードに直接書き込まれていないか |
パフォーマンス:不必要な負荷を生む実装を見逃さない
機能が正しく動いていても、パフォーマンスの問題があれば本番環境のユーザー体験や運用コストに影響します。特に以下の点に注目します。
| 確認項目 | チェックのポイント |
|---|---|
| ループ内の重い処理 | ループのなかで毎回DB接続・API呼び出しが発生していないか(N+1問題) |
| 不要なメモリ確保 | 大きなデータ構造を不必要に生成・保持していないか。リソースが適切に解放されているか |
保守性:将来の変更に耐えられる設計になっているかを確認する
保守性は「今動くか」ではなく「半年後に安全に変更できるか」という視点で評価します。
長期的なシステムの健全性を保つために欠かせない観点です。
| 確認項目 | チェックのポイント |
|---|---|
| 設計原則の遵守 | SOLID原則(単一責任・開放閉鎖等)・DRY原則(重複排除)に沿った設計になっているか |
| テストコードの品質 | ユニットテスト・統合テストが実装されているか。テストが実際のバグを検出できる内容になっているか |
規約準拠:チームのコーディング規約・スタイルガイドと一致しているか
コーディング規約への準拠確認は、ESLint・Pylint・Checkstyle等の静的解析ツールで自動化できる部分が多くあります。
自動化できる範囲はツールに任せ、人間のレビューは設計・意図・文脈の確認に集中するという棲み分けが効率的なレビューの基本です。外国人エンジニアが多いチームでは、規約ドキュメントを英語でも用意することを推奨します。
コードレビューの指摘密度の目安|IPAデータによる定量的ベンチマーク
「指摘が少なすぎる」「多すぎる」を判断する基準として、IPAの「ソフトウェア開発データ白書」のデータが参考になります。
同データによると、コードレビューの1万行あたりの平均指摘密度は約25件とされています。
この数値を目安に、チームの現状を評価できます。指摘密度が極端に低い場合(1万行あたり数件以下)は、レビューが形骸化しているサインです。詳しくはH2-8で取り上げます。
出典:IPA「ソフトウェア開発データが語るメッセージ 2015」(note解説記事より)
:IPA「ソフトウェア開発データ白書」
6. コードレビューを効率化するツール|自動化で人間の判断コストを減らす

静的解析ツール・プラットフォーム・AIツールを組み合わせることで、レビューの工数を削減しながら品質を高められます。
静的解析ツールは機械的なルール確認を自動化し人間の判断コストを下げる
「規約準拠」「構文エラー」「型の不整合」といった機械的に判定できる項目は、静的解析ツールで自動チェックできます。代表的なツールを以下に示します。
| ツール名 | 対応言語 | 主な機能 |
|---|---|---|
| ESLint | JavaScript / TypeScript | コーディング規約チェック・潜在的バグの検出 |
| Pylint | Python | コードスタイル・論理エラー・型ヒントの検証 |
| Checkstyle | Java | Googleスタイルガイド等の規約への準拠確認 |
| RuboCop | Ruby | Rubyの規約ガイドに沿ったスタイルチェック |
これらをCI(継続的インテグレーション)パイプラインに組み込むことで、プルリクエストが作成された時点で自動チェックが走り、機械的な問題をマージ前に弾けます。
人間のレビュアーは「設計の妥当性」「意図の整合性」といった、ツールでは判断できない観点に集中できます。
GitHubとGitLabはプルリクエスト・マージリクエストでレビューの中心的なインフラとなっている
現代のコードレビューのインフラとして、GitHubとGitLabの2大プラットフォームが中心的な役割を担っています。
コードレビューに必要な機能を一通り備えており、主な機能は以下のとおりです。
- 差分表示:変更前後のコードを行単位で並べて表示し、変更内容を直感的に把握できる
- インラインコメント:特定の行・コードブロックに直接コメントを付けられる
- 承認ルールの設定:「N名以上の承認が必要」「特定チームのレビューが必須」といった保護ルールを設定できる
- CODEOWNERS設定:特定のディレクトリ・ファイルに対して自動でレビュアーをアサインできる
どちらもグローバルスタンダードのツールで、外国人エンジニアにとっても使い慣れたプラットフォームです。共通のワークフローで開発に参加できるため、国際的なチームでもスムーズに機能します。
AIレビューツールの導入でバグ検出率と承認率が向上している
AIを活用したコードレビュー支援ツールの導入が急速に進んでいます。
GitHub Blogによると、AIと人間が協調してレビューを行った場合、コードの承認率が約5%向上すると報告されています。
代表的なAIレビューツールを以下に整理します。
| ツール名 | 提供元 | 主な特徴 |
|---|---|---|
| GitHub Copilot(コードレビュー機能) | GitHub / Microsoft | PRのコード変更に対してAIが自動でレビューコメントを生成する |
| Amazon CodeGuru | AWS | 機械学習を活用したセキュリティ・パフォーマンス問題の自動検出 |
| Codacy | Codacy | 多言語対応の静的解析+技術的負債の可視化 |
| GitLab Duo | GitLab | GitLab上でのAI支援レビュー・コード説明機能 |
国内ではCyberAgentが、LLM(大規模言語モデル)とTF-IDFを組み合わせた自動コードレビューシステムを開発した事例があります。
同社の技術ブログでは実行コストとレビュー精度のトレードオフも分析されており、導入を検討する際の参考になります。ただし、AIはあくまで補助であり、設計判断の最終責任は人間のエンジニアにあります。
出典:GitHub Blog「GitHub Copilotはコード品質を向上させるか?データが語る真実」
:CyberAgent Developers Blog「2024年度開発研修 最優秀チームのお手軽自動コードレビュー & 推薦システム Cookbook」
7. コードレビューのコミュニケーション|チームの関係を壊さない指摘の技術

技術的に正しい指摘でも、伝え方を誤るとチームの雰囲気を損ないます。関係を壊さずフィードバックするための実践的なポイントをまとめます。
コードを批判してもコードを書いた人を批判してはならない
コードレビューで最も大切なコミュニケーションのルールは、「コードの問題を指摘するとき、書いた人の人格や能力は批判しない」ことです。
指摘の主語を「コード」に置くことで、個人への評価ではなくコードの品質に焦点を当てたフィードバックができます。
| 区分 | コメント例 | 問題点 / 効果 |
|---|---|---|
| ❌ 悪い例 | 「なぜこんな書き方をしているんですか?理解できません」 | 書いた人への批判と受け取られ、防衛的な反応を引き起こす |
| ✅ 良い例 | 「このコードはネストが深くなっているため、早期リターンを使うと読みやすくなります」 | 問題点と改善方向が明確で、次のアクションを取りやすい |
| ❌ 悪い例 | 「これはおかしいと思います」(理由なし) | 根拠がなく、修正の方向性も不明 |
| ✅ 良い例 | 「このコードは外部入力のバリデーションがないため、SQLインジェクションのリスクがあります。OWASPのガイドラインに従い、プリペアドステートメントの使用を検討してください」 | 根拠・リスク・代替案がセットで示されており、修正の質が高まる |
日本語の婉曲表現(「〜ではないでしょうか」「〜かもしれません」)は、日本人同士では配慮として機能しますが、外国人エンジニアには「問題があるのか」「単なる提案なのか」が伝わりにくいことがあります。
多国籍チームでは、「このコードには〇〇の問題があります。△△への修正を提案します」という直接的な書き方の方が誤解が生じにくいです。
指摘には必ず根拠と代替案をセットで示すことがレビュアーの責務である
「なぜそうすべきか」の説明がない指摘は、修正の判断をレビューイに丸投げするものであり、修正の質を下げます。
根拠+問題点+代替案の三点セットでコメントする習慣を持つことがレビュアーの責務です。
コーディング規約・公式ドキュメント・セキュリティガイドライン(OWASP、NISTなど)へのリンクをコメントに添付する習慣を推奨します。
外部の情報源に根拠を紐づけることで、個人の好みではなくチームの共通基準に基づいた指摘であることが明確になり、グローバルチームでの共通言語にもなります。
良いコードには積極的に肯定フィードバックを伝えることで心理的安全性が高まる
コードレビューを「指摘される場」として捉えているエンジニアは少なくありません。
しかし、問題の指摘だけで肯定フィードバックのないレビューは、チームの心理的安全性を少しずつ損ないます。以下のような具体的な肯定コメントを積極的に伝えましょう。
- 「このエラーハンドリングの設計はきれいです。他の箇所にも同じパターンを使えそうですね」
- 「パフォーマンスの改善がはっきり見えます。ベンチマーク結果も参考になりました」
- 「複雑なロジックがうまく整理されており、コメントの説明も的確です」
良いコードを明示的に評価する文化はレビューイのモチベーションを高めるとともに、「何が良いコードか」をチーム全体に示す教育的な効果もあります。
レビューにかける時間と変更行数には効果的な上限の目安がある
SmartBear社の調査では、1回のレビューは60分以内、1PRの変更行数は400行以内が品質と効率を両立する目安とされています。
これを超えると集中力が落ち、見落としが増えます。400行を超えるPRが来た場合、レビュアーが「PRを分割して再提出してほしい」と依頼することも品質を守る正当な対応です。
出典:SmartBear社「Best Practices for Code Review」
8. コードレビューでよくある失敗パターン|形骸化・LGTM乱発・肥大化を防ぐ

運用が定着してからこそ陥りやすい落とし穴があります。形骸化・大規模PR・指摘のばらつきという3つの典型的な失敗パターンと対策を解説します。
レビューの形骸化はチームの品質基準が失われる最大のリスクである
コードレビューで最も深刻な失敗が形骸化です。「とりあえずLGTM」が常態化すると、レビューは品質担保の機能を失い、あるだけで安心感を与える”お守り”になってしまいます。
以下の状態が見られたら、形骸化のサインです。
- レビューコメントの指摘件数がゼロに近い状態が続いている
- PRが提出されてから数分以内に承認が付く
- 同じタイプのバグが繰り返しリリース後に発見される
IPAのデータが示す「1万行あたり平均約25件」という指摘密度を基準に、チームのレビューの健全性を定量的に評価できます。この数値を大幅に下回るようであれば、プロセスと文化を見直すタイミングです。
PRの変更範囲が大きすぎるとレビューの質が急激に低下する
SmartBear社の調査によると、変更行数が400行を超えるPRではバグ検出率が著しく低下します。変更箇所が多いほど「重要な部分に集中する」ことが難しくなるためです。
大規模なPRが発生しやすい原因として、以下が挙げられます。
- 機能を小さな単位に分割するスキルが不足している
- 「まとめて出した方が効率的」という誤った認識がある
- リファクタリングと機能追加を同一PRに含めている
対策として、「1PRは1つの目的に絞る」「リファクタリングは別PRとして分ける」「フィーチャーフラグを使って未完成の機能を小分けにマージする」といった習慣をチームとして推奨します。
出典:SmartBear社「Best Practices for Code Review」
指摘の粒度がバラバラだとレビューが属人化し標準化できない
レビュアーによって指摘の厳しさ・観点・粒度が大きく異なると、コードの品質が特定の個人に依存する状態になります。
あるレビュアーでは詳細に確認されるPRでも、別のレビュアーでは表面的にしか見られないという状況は、チーム全体の品質を不安定にします。
根本的な解決策はチェックリストの整備とレビュー基準の文書化です。2章で示した6カテゴリのチェックリストをチームのWikiやドキュメント管理ツールに整備し、全員が同じ基準でレビューできる環境を作ります。
コミュニケーション不足が原因で優秀なエンジニアがチームを離れるケースがある
指摘の仕方・受け取り方に起因する人間関係の悪化は、エンジニアの離職につながるリスクです。「自分のコードを否定された」という体験が積み重なると、心理的安全性が低下し、レビューへの関与意欲も失われます。
Googleの「Project Aristotle」研究では、心理的安全性の高さとチームのパフォーマンスに強い正の相関があることが示されています。
コードレビューのコミュニケーションの質は、エンジニア個人の仕事満足度と直結しています。2章で解説した指摘の技術をチームとして実践することが、この問題の根本的な防止策です。
9. AI時代のコードレビュー|人間が担うべき本質的な価値の再定義

AIがコードを書く時代、レビューの役割はどう変わるのか。最新データと理論をもとに、人間が集中すべき仕事を整理します。
AIがコードを書く時代に、レビューの量は増えてもその性質は変わりつつある
AIコーディング支援ツールの普及により、コードが生成されるスピードは大幅に上がっています。
ただし、それはレビューの負荷が下がることを意味しません。GitLabが実施した調査「AI Paradox」は、この逆説的な実態を明らかにしています。
同調査によると、AIの導入で開発スピードは上がった一方、コードレビューやコンプライアンス確認に週あたり平均7時間のボトルネックが生まれていると報告されています。
AIが大量のコードを生成するほど、人間がレビューすべきコードの量も増えるというメカニズムが「AI Paradox」の本質です。
| 要素 | AIによる影響 |
|---|---|
| コーディング速度 | 大幅に向上(AIが自動生成・補完) |
| コード生成量 | 増加(より多くのPRが生成される) |
| レビュー量 | 増加(PRの数に比例して増える) |
| コンプライアンス確認 | 負荷が増加(AI生成コードへの法的・倫理的チェックが新たに発生) |
| 週あたりのボトルネック | 平均7時間(GitLab調査) |
バグ発見はAIと自動化ツールに委ね、人間は「設計意図の共有」に集中すべきである
AI時代に人間が担うべき本質的な役割は、バグ発見よりも「設計意図(メンタルモデル)の共有」にあります。
コンピュータサイエンティストのPeter Naurが1985年に発表した論文「Programming as Theory Building」でも、これに通じる考え方が提唱されています。
Naurの理論を平たく言うと、「ソフトウェア開発の本質は、なぜそのように設計したかという理論(=メンタルモデル)をチームが共有し続けることにある」ということです。
コードそのものは、そのメンタルモデルの”結果”に過ぎません。
リスクになる場面
「コードは動いているが、なぜそうなっているかをチームが理解していない」状態は、改修・障害対応・近代化のすべての場面でリスクになります。
AIがコードを生成できるからこそ、設計の意図をドキュメント化してレビューを通じて共有するという人間の役割が、相対的に重要になっています。グローバルチームでは特に、設計意図の言語化・英語でのドキュメント化が大切です。
出典:Zenn「コードレビューとは何か」(Peter Naur理論の解説)
AI生成コードのレビューには設計判断の検証という新たな観点が求められる
AI生成コードをそのまま承認することには、人間が書いたコードとは異なるリスクがあります。
AIは「動作するコード」を生成する力は高い一方で、「チームのアーキテクチャ方針」「セキュリティポリシー」「将来の拡張性」を考慮した設計は行えません。
たとえば、技術的には正しく動くコードでも、以下のような問題を含んでいるケースがあります。
- チームのアーキテクチャ規約(レイヤー分離、依存方向など)を無視した設計になっている
- 本番環境のセキュリティ要件に準拠していない実装が含まれている
- 既存のユーティリティ・共通関数を再発明した重複コードが生成されている
「コードが正しく動くか」から「このコードをチームが理解しているか、設計原則に沿っているか」へとレビューの問いをシフトさせることが、AI時代のコードレビューの本質的な変化です。
| 確認観点 | YESの場合 | NOの場合 |
|---|---|---|
| コードは正しく動作するか | 次の確認へ進む | 修正依頼(バグ修正・再生成) |
| チームのアーキテクチャ方針に沿っているか | 次の確認へ進む | 設計の見直しを依頼 |
| セキュリティ・コンプライアンス要件を満たしているか | 次の確認へ進む | 修正依頼(セキュリティ観点) |
| チームがこのコードの設計意図を理解できるか | 承認(LGTM) | コメント・ドキュメント追記を依頼してから承認 |
AI Paradoxの解消策——ツールチェーンの断片化に対処する
ボトルネックの原因の一つはツールチェーンの断片化です。
AI支援ツール・静的解析ツール・CIパイプライン・セキュリティスキャナーなどが分散した環境では、それぞれの確認作業を個別に行う必要があり、レビュー全体の工数が膨らみます。
解消の鍵はプラットフォームの統合
たとえばGitLab Duoは、AIコード生成・セキュリティスキャン・コードレビュー支援・CI/CDを一つに統合することで、ツール間の連携コストを削減します。
GitHub Copilot+GitHub ActionsによるCI統合も同様のアプローチです。人間とAIの役割を整理すると、以下のようになります。
| 担当 | 主な役割 |
|---|---|
| AI・静的解析ツール | 構文エラー検出・規約チェック・セキュリティ脆弱性スキャン・パフォーマンスの警告 |
| 人間(レビュアー) | 設計意図の検証・アーキテクチャ方針との整合性確認・メンタルモデルの共有・コミュニケーション |
10.まとめ:コードレビューはチームで技術と信頼を育てる継続的なプロセスである

コードレビューは、バグ発見という個別の効果を超え、チームが同じ設計思想を共有し続けるための対話プロセスです。
観点の整備・コミュニケーションの工夫・ツールの活用・失敗パターンの回避・AI時代の役割整理を組み合わせることで、レビューは形式的な工程から組織の技術資産を守るインフラへと育ちます。
国内外のエンジニアが協働する開発現場において、コードレビューの質を高めることはチーム全体の競争力に直結します。
















